

I wasn’t impressed last week when I saw Brian Beach’s blog on what disk drive to buy. I wasn’t impressed due to the lack of intellectual rigor in the analysis of the data he presented. In my opinion, clearly Beach has something else going on or lacks understanding of how disk drives and the disk drive market work.
Let me preface this article with the following full disclosure: I own no stock in Seagate, WD, or Toshiba, nor do I have family or close friends working at any of those companies. I do not buy disk storage, as in my consulting role I am not allowed to resell hardware or software by agreement. I do know people in two of the three companies and have for years, but I have not been given free stuff nor would I take it. Basically, the only agenda I have is a comprehensive factual analysis, which in my opinion is lacking in Beach’s blog post.
Let’s start at the second table in Beach’s article. I have added a few columns in green that were not part of the original, but the information in these columns can be found on the web with a bit of work, and as you will see are pretty important.
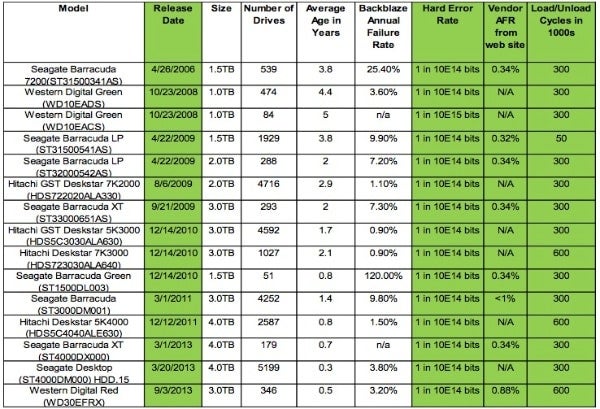
Let’s talk about the release data first. The oldest drive in the list is the Seagate Barracuda 1.5 TB drive from 2006. A drive that is almost 8 years old! Since it is well known in study after study that disk drives last about 5 years and no other drive is that old, I find it pretty disingenuous to leave out that information. Add to this that the Seagate 1.5 TB has a well-known problem that Seagate publicly admitted to, it is no surprise that these old drives are failing.
Now for the other end of the spectrum, new drives. Everyone knows that new drives have infant mortality issues. Drive vendors talk about it, the industry talks about it, RAID vendors talk about it, but there is not a single mention of what, if anything, is done in the Backblaze environment or how that figures into any of the calculations. This is never discussed in terms of: does Backblaze have a burn in period? Are they buying drives from someone that has burned in some and not others? There are lots of questions here.
Next let’s move to the hard error rate in bits. One of the definitions of consumer drives as compared to enterprise drives is that hard error rate is 1 bit in 10E14 bits for consumer drives and 1 bit in 10E15 bits for enterprise drives. The following table shows how many bits are moved before the storage vendors say there will be an error on the drive. So move about 11.3 TiB of data on a consumer drive and expect a failure.

Let’s analyze a few things that were stated and the implications. First the blog stated, “At the end of 2013, we had 27,134 consumer-grade drives spinning in Backblaze Storage Pods. The breakdown by brand looks like this:
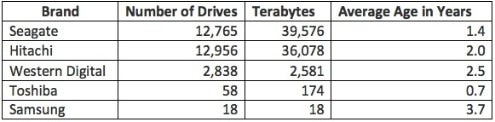
I’ve noted that we just found that the Seagate 1.5 TB drives are about 8 years old since release, for the failure rate, but the average age of the Seagate drives in use are 1.4 years old. Averages are pretty useless statistic, and if Seagate drives are so bad then why buy so many new drives? Yet this is not the big issue. There is nothing in the blog about how much data is written to a set of drives that has had failures. If the drive exceeds the manufacturer’s specification and it fails, while another drive that is not being read or written to as much does not fail, is that really a problem?
My answer is that you cannot discuss drive failures unless you state clearly that the amount of I/O being done to the drives is the same. You should expect that an 8-year-old drive – besides being beyond its life expectancy – has had more data read and written to it, so it’s approaching the hard error rate for the drive.
On a side note, it is interesting that the claimed failure rate of the Seagate Barracuda Green ST1500DL003 drives is 120%. Is that because 100% of the drives failed and were replaced with another 100% and then 20% failed, or what? Is the cause of the failure because, as was stated, “The drives that just don’t work in our environment are Western Digital Green 3TB drives and Seagate LP (low power) 2TB drives. Both of these drives start accumulating errors as soon as they are put into production. We think this is related to vibration. The drives do somewhat better in the new low-vibration Backblaze Storage Pod, but still not well enough.”
A simple read of the drive specification compared to other drives shows that this drive should not be used in high vibration environments. Does this mean that Backblaze engineering does not spend the time to read the drive specifications for each drive they purchase?
The next column is the vendor supplied AFR (Annualized Failure Rate), which Seagate supplies for most of their drives and WD supplies for a single drive. These numbers are the best case values for the drive to respond to a command. For the 1 drive that Seagate does not provide an AFR, the ST4000DM000, Seagate states in their manual that: Average rate of
So the specification for the drive, beside the vibration, operating temperature, and other specifications, now Seagate – and likely soon other drive vendors – will be specifying the amount of I/O that can be done to a drive in a year. 55 TB is the equivalent of ~105 hours of operation at 146 MB/sec (the drive average performance). ((55*1000*1000*1000*1000)/(146*1000*1000))/3600=104.6/((24*365) for the percentage per year). So why would anyone buy a drive for an online backup and restore operation that could support drive utilization using average performance of .12% for the year as per the vendor specification?
Now look at the last column. This is the number of drive load/unloads, which is where the sliders that carry the read/write heads in hard disk drives land on the disk media at power down, and remain stationed on the disk until the power up cycle. This has very little to do with reliability of the drive unless the values are exceeded, but is a good example of another limitation that manufacturers document for disk drives. It is not discussed anywhere in the blog.
What Matters in Disk Drive Research?
What matters in disk drive research is obtaining information beyond the surface of averages, and getting the raw numbers to do some basic analysis on data that really matters. You need to know:
1. The age of the drives as it affects the failure rate of the drive.
2. Whether the drives are burned in or not burned in, as it impacts the infant mortality.
3. How much data will be written to and read from each drive time and if over time the drives in question will hit the limits on the hard error rates.
4. The load and unload cycles and if any of the failures exceed manufacturer specification.
5. Average age does not tell you anything, and statistics such as standard deviation should be provided.
6. Information on SMART data monitoring and if any of the drives had exceeded any of the SMART statistics before they are more likely to fail.
7. Information on vibration, heat or other environmental factors as it impacts groups of drives. Will a set of new drives from a vendor get put into an area of the data center that is hotter or have racks with more vibration?
You must understand the manufacturer’s specifications in relationship to the planned usage. If, let’s say, you buy a commodity product like a home washing machine, but put it in a laundromat and it breaks after 3 months of usage, should you have expected it to last 3 years? I think the same question should be asked of anyone using consumer technology and a commercial application.
Next month I’ll discuss best practices in selecting a disk drive. Stay tuned.
Photo courtesy of Shutterstock.

?")
")
