Traditional data protection is three decades old and is definitely showing its age. Poor management oversight, data growth, virtualization, data silos and stricter SLAs all conspire to strain traditional backup to the breaking point. Traditional backup usually follows a set pattern: full baseline backup, daily incremental backup, full weekly backup. When backup volumes were smaller […]

Traditional data protection is three decades old and is definitely showing its age. Poor management oversight, data growth, virtualization, data silos and stricter SLAs all conspire to strain traditional backup to the breaking point.
Traditional backup usually follows a set pattern: full baseline backup, daily incremental backup, full weekly backup. When backup volumes were smaller and fewer, this process worked well enough. But a daily operation creates backup data that is missing up to 20 hours or more of current data input, making it impossible to restore to a meaningful recovery point objective (RPO).
The obvious solution is continuous backup with frequent snapshot recovery points. But this type of backup product can be expensive and resource-intensive, and IT often reserves it for a few Tier 1 transactional applications. But what happens to large and popular business applications such as email, back office files and content management systems? Failed backup and recovery can still devastate a business.
Let’s look at why traditional backup is so difficult to do well these days, and why the risk and expense are so high.
Using aging backup products may be painful but there is a lot of inertia around replacing them. IT knows very well that they have to buy software, update hardware, buy third-party products to fill in the gaps, migrate old backup data so it can be restored, and integrate the whole package with existing network tools. Overwhelmed IT departments often decide just to give the old backup one more year or buy a stop-gap tool just to get by. In the face of these pressures, the backup replacement had better be compelling and cost-effective enough to justify the switch.
This is where evolutionary backup technology appears front and center. Unified backup platforms are a strong trend because they extend unified data protection to applications, virtualized networks, physical networks and multiple operating systems. They are based on the concept of snapshots and changed block tracking for near-continuous backup, global dedupe, automatic backup verification and instantaneous restore.
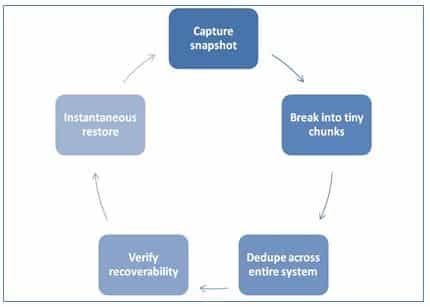
Figure 1. Optimal backup flow
Let’s take a look at the requirements for a next-gen backup platform.
For years, debates have raged over the use of agents in backup software. Agentless solutions do have benefits, such as no extra load on the protected server and no need for agent management features.
However, agent-based solutions have strong advantages as well. Agents provide application awareness such as the ability to gather metadata about the application including application versions and components, configurations, and the ability to truncate database logs.
Intelligent modern agents act in concert with the host to quickly carry out backup and recovery operations directly on the protected machines.
Furthermore, even an agentless system has to assign resources to backup and recovery operations. In their case, this intensive processing occurs in the host, which can require far more resources than distributing operations among agents.
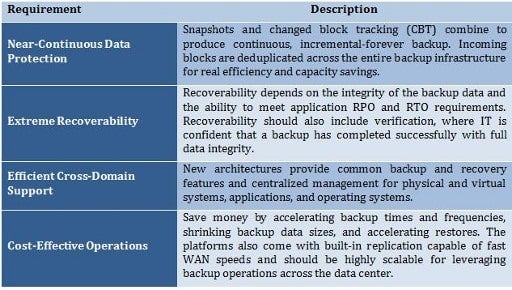
Near-continuous backup, near-immediate recovery and broad domain support are not easy to do. When you add in cost-effectiveness, you have a real challenge on your hands.
Vendors are certainly trying because there are rich rewards for success in the data center. Many backup vendors offer scalable solutions with centralized management. Some vendors concentrate exclusively on virtual networks, but the market leaders are attempting to protect a variety of environments in the backup infrastructure.
Running multiple backup tools can be complex and costly, and extreme data growth and virtualized networks are worsening the problem. We strongly suggest that IT consider platform backup technology that unifies backup needs across the data center, and that is founded upon scalability, ease-of-use and exceptional efficiency. The more backup operations that IT brings under the platform’s control, the greater the company’s return on investment.
Christine Taylor is an analyst specializing in data protection and information governance at Taneja Group.
Christine Taylor is a writer and content strategist. She brings technology concepts to vivid life in white papers, ebooks, case studies, blogs, and articles, and is particularly passionate about the explosive potential of B2B storytelling. She also consults with small marketing teams on how to do excellent content strategy and creation with limited resources.

Enterprise Storage Forum offers practical information on data storage and protection from several different perspectives: hardware, software, on-premises services and cloud services. It also includes storage security and deep looks into various storage technologies, including object storage and modern parallel file systems. ESF is an ideal website for enterprise storage admins, CTOs and storage architects to reference in order to stay informed about the latest products, services and trends in the storage industry.
Property of TechnologyAdvice. © 2026 TechnologyAdvice. All Rights Reserved
Advertiser Disclosure: Some of the products that appear on this site are from companies from which TechnologyAdvice receives compensation. This compensation may impact how and where products appear on this site including, for example, the order in which they appear. TechnologyAdvice does not include all companies or all types of products available in the marketplace.
