

Storage technology is evolving extremely rapidly but our file systems are not. Is it time to re-think files systems so we can take advantage of this new technology?
Enterprise SSD – And Much More
Perhaps it’s because I’m getting older but it seems like things are changing faster every year (my wife tells me it’s because I’m getting older).
Regardless of the cause, things are changing quickly, particularly in storage world. SSD’s are becoming very popular, pushing out spinning drives. We even have SSD’s coming with 60TB’s of capacity (link). Enterprise SSD’s are quickly impacting enterprise storage designs. Spinning drives are now coming in massive capacities courtesy of Shingled Memory Recording (SMR) technology that come in 10TB and 12TB capacities. Non-Volatile memory is on the horizon. Yet, some aspects of storage are not changing or not changing much at all to adapt to these new technologies.
As I’m sure everyone knows, storage is not just the storage device, or the network interfaces, or the controller. File systems are also part of storage. Management tools, network protocols, and even processes are part of storage. As with any new technology in computation/storage, new technology can move the bottleneck to a different place in the solution as a whole.
Then some new technology comes along and pushes the bottleneck out or moves the bottleneck to a different location in the solution. The important thing to realize is that if technology pushes a great deal in one direction, the other aspects need to adapt or they become a bottleneck.
I believe we are a point in storage where aspects of storage need to evolve or change and to do it quickly. One of those aspects is the file system.
Before jumping into file systems moving forward, let’s look at file systems of the past. I won’t go too far back only to where spinning disks became popular. This includes hard drives and floppy drives. This is rotating media where a mechanical “head” reads and writes information to the media. By looking down at the drive you can think of it as a cylinder. The “tracks,” which is where the data is written as concentric circles on the media, this is where the terms “cylinder,” “track,” “head”, etc. come from. However, the physical layout of today’s hard drives don’t correspond to the geometry anyway. It is simply used as a vestige of the past.
File systems store the data and the metadata (data about the data). In general, Linux views all file systems using a common set of objects: (1) superblock, (2) inode, (3) dentry, and (4) file. The superblock is at the root of the file system and maintains state for the file system.
The inode, one of the most fundamental parts of a file system, represents all files and directory objects. It contains all the metadata to manage the objects including the permissions. Dentries are used to translate between inodes and names. Typically there is a directory cache that keeps the most recently used translations around (faster lookups). It also maintains the relationships between directories and files.
And finally, a VFS (Virtual File System) file represents an open file. This is done to keep the state for an open file as the write offset, etc.
Enterprise SSD – A Look Inside
Solid State Disks (SSD’s) use solid-state storage instead of spinning disks for storing data. The drive is constructed of flash memory. The most common cell used in SSD’s is the NAND Flash. For this device, the transistors are connected in series. These groups are then connected in a NOR style where each line is connected directly to ground and the other is connected to a bit line. This arrangement has advantages for cost, density, and power as well as performance but it is a compromise as we shall see.
In NAND Flash memory the cells are first arranged into pages. Typically, a page is 4KB in size. Then the pages are combined to form a block. A block, illustrated below in Figure 2, is many times formed from 128 pages giving a block a size of 512KB.
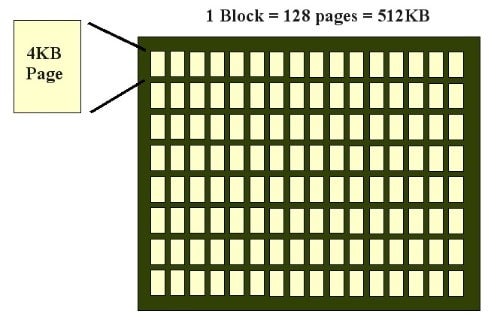
BlockView of NAND Flash
The blocks are combined into a plane. In many cases, a total of 1,024 blocks are combined into a plane, giving it a size of 512MB as show in Figure 3.
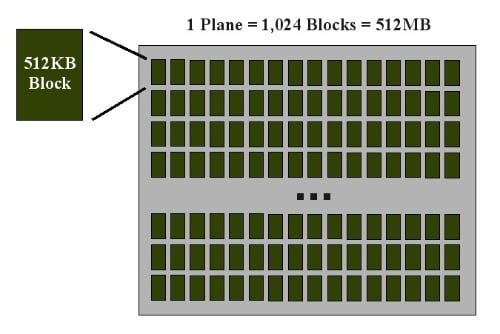
Plane View of NAND Flash
There will almost always be multiple planes in a single NAND-flash die. Manufacturers will also put several dies into a single NAND flash chip. Then you can put multiple chips in a single drive.
Data can be read from SSD’s a single bit at a time but writing data to the SSD has to be done in blocks. This is a result of the chip layout and can cause issues with write operations to SSD’s. To write even a single bit to a specific block on the SSD that contains data, requires that the data on the targeted block is first read and stored in memory. Then the block data in memory is updated with the new data and then written to an open block on the drive.
As you can imagine doing write IOPS to SSD’s can be a difficult task, especially if the data is spread all over the blocks. While SSD’s naturally have amazing performance to begin with, the probability of doing lots of updates to blocks can get fairly large. Drive manufacturers use all sorts of techniques to improve the data update on SSD’s but the interaction between the hardware design and the file system still causes problems.
SMR
Shingled Magnetic Recording (SMR) drives have been out for a few years and are increasingly popular. Compared to “classic” hard drives, SMR drives reduce the guard space between tracks and overlap the tracks. The figure below is a diagram that illustrates this configuration.
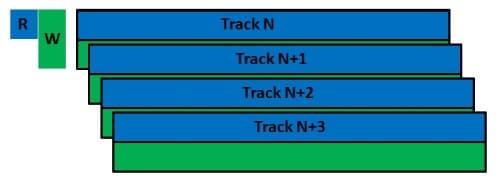
SMR hard drive track layout
The tracks are overlapped so they look like roof shingles, hence the name “Shingled Magnetic Recording”.
The diagram shows that the write head writes the data across the entire track (the blue and green stripes in a specific track). But the drive “trims” the data to the width of what the read head actually needs to read the data (this is the blue area of each track). This allows the areal density, the number of bits in a specific unit area, to be increased, giving us more drive capacity (and who doesn’t like more drive capacity)
In the case of a write to an SMR drive, the write head will write data using the full width (green), before trimming the data (blue). For example, if the write head in yellow needs to write data to the drive, the write head writes to the current track, such as Track N+1 as in the figure below.
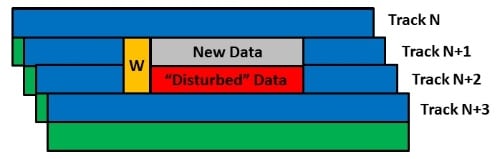
“Disturbed data” track layout
Because of the width of the write head, data is written to Track N+2 as well as N+1. After writing the data, it is trimmed. The post-trimmed data is show as “New Data” and the data it will over-write is shown as “Disturbed Data” and is in red. This data already exists and will be over written if the “New Data” is written.
To get around the problem of data over-write, the drive has to read the data that is about to be over written and write it somewhere else on the drive. After that, the drive can write the new data to a location that, hopefully, doesn’t already have data stored in neighboring tracks. Therefore a simple write becomes at least a read-write-write (one read and two writes). I’m not counting the “seeks” that might have to be performed but you can see how a simple data write with existing neighboring data can lead to a large amount of activity adversely impacting the performance.
In an additional scenario, if a block of data is erased there is suddenly a “hole” in the drive that a file system will likely use at some point. There may be data on neighboring tracks surrounding the hole. A typical file system doesn’t know that an unused block may or may not have neighboring tracks with data so it may be decide to write into that block. Therefore the disk will experience a read-write-write situation again.
IO elevators within the kernel try to combine different writes to make fewer sequential writes rather than a large number of smaller writes that are possibly random. This can help SMR drives but only to a certain degree. To make writing efficient the elevator needs to store a lot of data and then look for sequential combinations. This results in increased memory usage, increased CPU usage, and increased write latency. The result is that the write speed can be degraded for both sequential write IO and random write IO depending upon where the data is to be written.
How to Handle the Changes?
These are but just two examples of the changes in storage media. With SSD’s, the performance is amazing, the media no longer rotates (it’s now chips), it can jostle them around without fear of crashing the drive, individual byte writes can be very costly, and they have a limited life albeit a fairly long one. With SMR drives, the density has gone up which is wonderful (more storage capacity), but a small write to an existing piece of data or to a location on the drive where data already exists (or even close to where it exists), causes a performance slow-down.
You can take almost any file system today and use it on an SSD or a SMR drive. But it might not work as well as you hope because of the characteristics of the storage. File systems are adapting to storage media but they can only go so far without having to change. The question we face is: should we keep adapting current file systems to new storage or should be call a time-out and develop something new?
I am of the personal opinion that while we still have file systems that work with current storage, we should be looking to develop something new. This “something new” should take advantage of the storage technology to improve performance and ease of use.
For example, SMR drives need a file system that has some awareness that it is much more of sequential media than a random IO media. This may mean doing something with the media data as well since that can appear like random IO’s to a drive, especially if you allow the file system to update the access time every time the file is accessed.
In the case of SSD’s we need to rethink file systems so we don’t try to force the classic rotating mentality to “chip” based storage. While file systems and tools are adapting to SSD’s, SSD’s are evolving as well. Also remember that SSD’s have the problem that if you update a single byte in a block, then the whole block needs to be re-written. This also means that random IO’s should be re-thought so to limit this behavior (Note: current SSD’s have techniques to limit the re-write issue but they don’t completely solve the problem).
We can even start to think a it more outside of the box and develop a specific file system for each storage type (e.g. SMR, SSD). However, we also need them to work together in case we have a combination within a single system. For example, could SMR drives just hold large sequential chunks of data while the metadata and small files are stored on SSD’s? We might get the best of both worlds – inexpensive capacity (SMR drives) and very fast performance (SSD’s).
To achieve this, do we need to create some sort of “segmented” file system that adapts to various storage types that also adapts to having multiple segments in use at the same time? Is there a common interface between segment types so that people can write file systems that adpat to the storage?
While I’m not a huge fan of POSIX in the fact that it can really limit parallel performance, I still think POSIX capability is needed. But we should take the opportunity to offer additional options for applications. For example, can we offer a simple key-value IO interface? Or can we offer a simple database interface?
Given how long it takes to design a file system, write it, and stabilize it, we, as a community need to start thinking about what we want for the future and what it should look like.

?")
")
