


Object-oriented storage is becoming very popular. It’s being used for websites, medical records, databases, Hadoop, general data media storage, and more. One of the big draws of object oriented storage is its simplicity. There are only a few commands for object based file systems:
- PUT (basically a “write” — PUT the object into the storage)
- GET (basically a “read” — GET the object from the storage)
- DELETE (delete the object which is the file)
- POST (dds an object using HTML forms — similar to PUT but using HTML)
- HEAD (returns an object’s metadata but not the data itself)
The POST and HEAD commands are not universal, but you do see them in object storage systems that are compatible with AWS S3.
On the other hand, tried-and-true POSIX file systems that have a massive range of data access functions. Below is a partial list of IO functions for Linux:
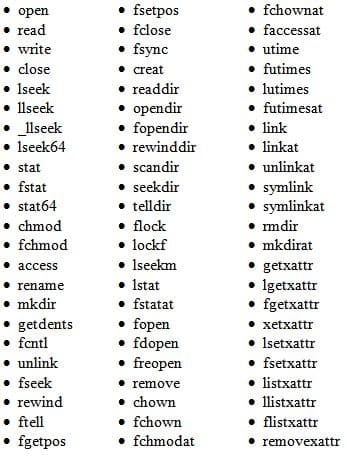
This is only a partial list of POSIX IO functions including some of the extended attributes. There are many more.
Object-oriented storage systems are really an all-or-nothing situation. You can’t do any byte-level file access like you can do with POSIX. When you read a file, you get the entire file via the GET function. Your application has to handle the data in the file. This means you have to port or rewrite your application to adapt to the storage paradigm.
Intermediaries
There are some object-storage intermediaries that provide a gateway to/from the object-storage system and POSIX-compliant applications. Examples include the following:
These solutions GET/PUT complete files from the object storage to a local file system. The POSIX applications interact with the data on the local file system (which is POSIX-compliant). The intermediaries then copy the data to/from the object storage systems.
The concept of the intermediaries is good, but the devil is always in the details. How often do you synchronize data from the local file system to the object storage? What if the POSIX application is doing lots of small byte IO with the data files on the local storage? How and when does the intermediary move the data to/from the object storage? What happens if the local storage crashes? How is data consistency insured?
There are many, many more questions about these intermediaries, but in many cases they are the best solution available to handle data movement to/from the object storage for you.
One of the more fully featured tools is s3ql. It acts as an intermediate file system between S3 and local applications. It is POSIX-compliant so applications can run using the storage without worry. It handles hardlinks, symlinks, standard permissions, extended attributes and file sizes up to 2TB. It also has some additional features unique to s3ql, including the following:
- Encryption
- Compression
- De-duplication
- Copy-on-Write/Snapshotting
- Dynamic Size
- Transparency
- Immutable trees
- Range of backends
- Caching
What Is Needed?
Object storage systems are popular for many reasons, most notably simplicity, ease of use, and cost (at least compared to NAS systems). On the other hand, people complain that applications have to be rewritten to use the storage and that they are slower than other forms of storage.
POSIX file systems are the most common storage system in use today. The POSIX compliance provides a wide range of IO functions for applications to use, including byte-level access. However, with the large number of IO functions comes complexity, both for the application and the file system. Typically POSIX storage is faster than object storage but also a bit more expensive.
As a result, people using object storage want faster performance and byte-level access while retaining the simplicity, ease of use, and the cost. People using POSIX storage would like things to be simpler, approaching that of object storage, and they would like the cost to come down.
At this point, I would normally insert a picture of the rainbow unikitty with butterfly wings and say good luck. However, I think it might be possible to combine object-storage and POSIX to create something that comes close to the ideal.
Object-POSIX?
What really is needed is a hybrid file system that contains some of the aspects of object storage and some of the aspects of a POSIX file system. An obvious starting point is to either add the object storage functions (GET/PUT/DELETE) to POSIX, or to add some POSIX functions to object storage. In either case, the interesting part is trying to find the balance between object-oriented storage and POSIX. Adding too many functions to object storage makes the result look much more like POSIX. Conversely, if not enough functions are added to the object storage, then it won’t be as easy to port applications.
For either approach the overall general goals, at least in my mind, should be the following.
- Simple to use
- Only a few additional IO functions
- Allow easy porting of POSIX IO applications
- Add byte-level access in some fashion to object storage or object storage functions to POSIX storage.
The controversial addition is the last one — adding byte-level access to object storage or adding object functions to POSIX.
In my opinion, and I’m sure there will be people who won’t agree with it, it is better to start with the simple object storage and add the needed functions to it. The biggest reason for this choice is simplicity. Object storage is very simple in concept with a very few IO functions. In addition, while people have been sold on the idea of object storage, they have found that writing applications to use it directly is really not easy. Therefore, I think it’s better to start with object storage and add a few useful byte-level functions so that it’s infinitely easier to port applications to use object storage. Here is my list of initial functions to add to object storage.
There are some specific reasons I chose just these five functions and not more (or less).
If byte-level access is going to be added to object storage an “open” function will be needed that returns a file descriptor that can be used throughput the application. To get an idea of what this function entails, an excerpt of the POSIX “open” manpage from Linux is listed below:
open():
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int creat(const char *pathname, mode_t mode);Given a pathname for a file, open() returns a file descriptor, a small, nonnegative integer for use in subsequent system calls (read(2), write(2), lseek(2), fcntl(2), etc.). The file descriptor returned by a successful call will be the lowest-numbered file descriptor not currently open for the process.
By default, the new file descriptor is set to remain open across an execve(2) (i.e., the FD_CLOEXEC file descriptor flag described in fcntl(2) is initially disabled; the O_CLOEXEC flag, described below, can be used to change this default). The file offset is set to the beginning of the file (see lseek(2)).
A call to open() creates a new open file description, an entry in the system-wide table of open files. This entry records the file offset and the file status flags (modifiable via the fcntl(2) F_SETFL operation). A file descriptor is a reference to one of these entries; this reference is unaffected if pathname is subsequently removed or modified to refer to a different file. The new open file description is initially not shared with any other process, but sharing may arise via fork(2).
The argument flags must include one of the following access modes: O_RDONLY, O_WRONLY, or O_RDWR. These request opening the file read-only, write-only, or read/write, respectively.
The “open” function creates the file descriptor which can then be used by subsequent IO functions such as read, write and lseek. The descriptor will around as long as the application is running.
In addition to “open” we’ll need the equivalent “close” function. Below is an excerpt of the POSIX close manpage from Linux:
close():
int close(int fd);close() closes a file descriptor, so that it no longer refers to any file and may be reused. Any record locks (see fcntl(2)) held on the file it was associated with, and owned by the process, are removed (regardless of the file descriptor that was used to obtain the lock).
If fd is the last file descriptor referring to the underlying open file description (see open(2)), the resources associated with the open file description are freed; if the descriptor was the last reference to a file which has been removed using unlink(2) the file is deleted.
These two functions, open and close, give us the ability to create access to the data for the application at a byte level.
Now we need functions that allow us to do byte-range IO to the file. You can probably imagine the first IO functions, which are “read” and “write”. Below is an excerpt of the POSIX read function manpage for Linux:
read():
ssize_t read(int fd, void *buf, size_t count);read() attempts to read up to count bytes from file descriptor fd into the buffer starting at buf.
On files that support seeking, the read operation commences at the current file offset, and the file offset is incremented by the number of bytes read. If the current file offset is at or past the end of file, no bytes are read, and read() returns zero.
If count is zero, read() may detect the errors described below. In the absence of any errors, or if read() does not check for errors, a read() with a count of 0 returns zero and has no other effects.
If count is greater than SSIZE_MAX, the result is unspecified.
In addition to the read() function, there should also be a write() function. Below is an excerpt of the Linux man page for the write() function:
write():
ssize_t write(int fd, const void *buf, size_t count);write() writes up to count bytes from the buffer pointed buf to the file referred to by the file descriptor fd.
The number of bytes written may be less than count if, for example, there is insufficient space on the underlying physical medium, or the RLIMIT_FSIZE resource limit is encountered (see setrlimit(2)), or the call was interrupted by a signal handler after having written less than count bytes. (See also pipe(7).)
For a seekable file (i.e., one to which lseek(2) may be applied, for example, a regular file) writing takes place at the current file offset, and the file offset is incremented by the number of bytes actually written. If the file was open(2)ed with O_APPEND, the file offset is first set to the end of the file before writing. The adjustment of the file offset and the write operation are performed as an atomic step.
POSIX requires that a read(2) which can be proved to occur after a write() has returned returns the new data. Note that not all file systems are POSIX conforming.
At this point there are open() and close() functions for an object, and there are also read() and write() functions. The last function that is needed to complete basic byte access is lseek(). This IO function is both a curse and a blessing. It can be used to move the file pointer to a new position. The blessing is that it can be very useful for byte-range access in a file and/or deal with complicated data patterns.
An excerpt of the man page for lseek for Linux is below:
lseek():
off_t lseek(int fd, off_t offset, int whence);The lseek() function repositions the offset of the open file associated with the file descriptor fd to the argument offset according to the directive whence as follows:
- SEEK_SET – The offset is set to offset bytes.
- SEEK_CUR – The offset is set to its current location plus offset bytes.
- SEEK_END – The offset is set to the size of the file plus offset bytes.
The lseek() function allows the file offset to be set beyond the end of the file (but this does not change the size of the file). If data is later written at this point, subsequent reads of the data in the gap (a “hole”) return null bytes (aqaq) until data is actually written into the gap.
With these few IO functions, the world of byte-range access to object files is opened. Now you have the option of reading only part of an object instead of having to GET the entire file. This opens a vast new set of possibilities.
For example, an application might need to read the first n bytes of a number of files to gather information and present it to the user. With object storage systems, all of the data needs to be first downloaded from the object store to a POSIX file system and read the files. That is a tremendous amount of data movement. With an object-POSIX combination, the files could remain in the object store and the first n bytes read from the file.
You can actually put numbers to this example. Imagine having 100 files that are 100MB each. If you need to read the first 16KB of each file, then you are only reading a total of 1.6MB of data. However, if the files are stored in an object store you have to first copy 10 GB worth of data from the object store to a POSIX file system. Then you have to read the 1.6MB of data. That’s 1.6MB versus 1001.6MB (a few orders of magnitude difference).
This is a wonderful result of adding byte-range functions to object storage — the amount of data either accessed or touched, is much smaller than a pure object storage solution.
The Case for Combining Object Storage and POSIX Storage
People who use object storage want it to behave more like POSIX storage, but they also want to keep the storage costs at an object level and improve the performance. People who use POSIX file systems like the simplicity of object storage systems and also want the price to come down to object storage levels. In other words, both sides want the rainbow unikitty butterfly.
I think it’s important to consider what these two groups want. Having an object storage system that allows byte range access is very appealing. It means that rewriting applications to access object storage is now an infinitely easier task. It can also mean that the amount of data touched when reading just a few bytes of a file is greatly reduced (by several orders of magnitude).
Think about it. Conceptually the idea has great appeal. Because I’m not a file system developer I can’t work out the details, but the end result could be something amazing.
Photo courtesy of Shutterstock.