

Like two fencers in a dark room separated by 50 feet, both users and vendors will insist that they are stabbing in the right direction. Are you asking for vendor benchmarks for configurations that match your applications? Are vendors testing storage solutions with tests that approximate your applications on configurations that you will purchase?
Nose Your IO Patterns
In my previous article, I talked about a new benchmarking reality where the benchmarks should include the performance during a drive rebuild and report the amount of time for the drive rebuild to finish while under load. I made a comment in that article, “… As a side note it is quite common for customers to request a configuration that doesn’t match their IO patterns and workloads just because of either folklore, urban myths, or just because it’s easy, rather than actually characterize the IO patterns of their applications. …”. I want to talk about this statement in this article because of a very, very important concept that people miss—knowing the IO pattern of your application(s).
Let’s do a simple experiment. Write down the top three applications on your system. These can be the ones that use the most CPU time or the ones that are run the most often or the ones that use the most data or the ones that seem to be most IO intensive or even the ones that seem to run the slowest. Think about how these applications do IO and write down what you believe is the IO pattern.
It’s definitely not easy is it? Believe it or not, even application developers have a difficult time telling you how their applications do IO.
All developers can tell you that at certain points during the execution of the application IO will be performed. And they can sometimes tell you which language IO functions are used (e.g. fwrite(), fread(), write(), read() in the case of C and C++) but that is about it. They are usually focused on the algorithm itself and not so much on how the data gets into or out of storage.
Of course, I don’t really blame them because the algorithms are difficult enough without having to focus on the IO pattern of their application. However, what this means is that it is almost impossible to design a storage system that meets the IO needs of the application. It’s as if you go to a shoe store to buy size 10 tennis shoes and walk out with flip-flops that are size 15 and a pair of yellow socks. This will become even more acute as the data growth accelerates.
If you are able to describe and demonstrate the IO pattern of your application(s) then you are one of the few that I know that can do that. Pat yourself on the back, publish the results and process(es) you used, and please help others do this. But for the remaining 99.9 percent of us in the world, describing IO patterns can be very difficult. We have to start somewhere so let’s by start by using some of the typical metrics that describe IO patterns.
Start at the Starting Line
The most fundamental question you can answer about the IO pattern of your application is “Does IO take up a significant portion of the run time?” In other words, “Is IO important?”
Believe it or not, this question is also not easy to answer precisely. You have to be able to measure the amount of time spent doing IO without unduly impacting the overall run time of the application. But there is a simple way of doing this for many applications—strace.
Strace is the system tracing tool in *nix operating systems. It traces system calls and can generate quite a bit of information, such as the completion status (did it complete?), the parameters of the system call, the elapsed time to complete the system call, and in the case of reads and writes, the success of the function (how much data was actually written or read?). With this information and a little work you can examine the IO pattern of applications.
Virtually all IO is done via system function calls, so strace should be able to capture quite a bit of IO information.
One word of caution—if the application is doing mmap IO where it doesn’t use system IO functions, then strace won’t be helpful. But if you are using mmap IO then you have other issues so understanding the IO pattern may not be a high priority.
The strace information provides some insight into the IO requirements from an application’s perspective. It gives you the system function calls, including the IO ones, that the application makes to the operating system. In other words, the IO that the application is making to the system. There are several layers that data has to traverse to actually get to the storage media, but that is within the operating system and not a function of the application.
Below is a snippet of some strace output from a simple example that writes some data structures.
1373231279.242784 write(3, "1���2���3����� A2���3���4�����240A"..., 4096) = 4096 1373231279.242921 write(3, "11��21��31���240 E21��31��41���@!E"..., 4096) = 4096 1373231279.243064 write(3, "12��22��32���P240E22��32��42���240240E"..., 4096) = 4096 1373231279.243188 write(3, "13��23��33���P360E23��33��43���240360E"..., 3712) = 3712 1373231279.243283 close(3) = 0
For this example I used the “-T -ttt” options with strace to get the execution time of each system function (the last number in the ).
In the above strace snippet, the first number on each line is the number of seconds since epoch that mark the start time of the function. The number of bytes actually written is also shown after the “=”. The amount of data just before the “)” is the amount of data that is requested to be written and the amount of data after the “=” is the actual amount of data written.
For the above snippet, 4KiB was sent to the operating for the first three writes and 3,712 bytes in the fourth write. This is the amount of data sent to the write() system function which then sends the data down into the operating system and ultimately to the storage media.
But the OS has buffers and will try to combine (coalesce) data requests that are next to one another to improve the overall performance. Strace output cannot gather that information—it only shows the data from the system function to the system. But the important point is that strace gathers the IO patterns from the perspective of the application.
The C code corresponding to the previous strace output is from the C function “fwrite.” This function buffers the amount of write data until it reaches a certain limit, in this case 4 KiB, before executing a write() system function. It is possible to use greater buffer sizes (good article here) but this requires some work on the developer’s part.
Right away, using the strace output, you can see the amount of data the application is sending to the operating system per write function. If you like, you can think of this as the “data size” or “write size” from the application (the same applies to reads as well as writes). You can scan a complete strace output file and then get a range of write sizes for the application. In fact, you can plot a histogram of these as shown in the example below which plots a histogram of the write sizes in the byte range (0-1KB).
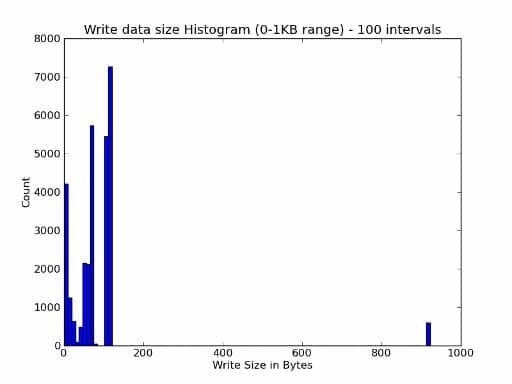
Figure 1: write size histogram example
This histogram can be very useful when discussing a storage solution with vendors. You can show them the histogram and explain that the information comes from an strace of the application. Then you can ask them to do the same thing or at least provide the same information for the tests/benchmarks they ran. If the patterns are similar, then their tests/benchmarks are perhaps useful relative to your application. You don’t have to match the entire histogram either, you can just match snippets or sections of it.
You can also take the amount of data in each write function call and divide by the amount of time it took to complete. This gives you the throughput of that function call. This can also be useful information, although the merging of write or read calls as well as caching can affect the time. But at least it gives you some sort of throughput information (there are other sources of approximate throughput information for an application but that’s another long article).
Would You Like Your Data Sequential or Random?
In addition to the size of the IO system calls, another very important aspect of an IO pattern is understanding if it is a sequential or random data access pattern (or a combination). Sequential access means that your application accesses a certain piece of data in a file (read or write), and the next access proceeds from where the prior access ended. There is no movement of the file pointer in between data access via an lseek() function or a rewind() function or something similar. A simple example of this is to read 4 KiB from a file and then read the next 4 KiB in the file and so on.
A random access IO pattern accesses some data in a file and the next data access is not the next chunk of data but some other data chunk within the file (ideally, a random location). A simple example is to read 4 KiB from a file, then move the file pointer to a point of 18 KiB within the file and read another 4 KiB. This example skipped the data from the end of 4 KiB to 18 KiB before doing another IO operation and 18 KiB is not a multiple of 4 KiB making the file pointer location a little more random. If you do this pattern in a seemingly random pattern then it is considered a random file access IO pattern.
You can use strace information to examine the sequential or random nature of data access. You just scan through the strace file at zero. After a 4,096 byte read of a file the file pointer is at 4,096 (the strace output for a read() function tells you how much data was read in bytes). An lseek operation tells you the final file pointer location in bytes. The same is true for other functions that modify the current file pointer. Then you just plot the file pointer location as a function of time.
If the file is accessed purely sequentially, the plot of a file pointer over time should have the file pointer value increasing in a monotonic fashion for longer stretches of time. But there may be times when the file is closed and reopened which will set the file pointer back to the beginning (a value of zero). A common example is reading an input file where you read it from beginning to end so the file pointer plot should just be an increasing value.
On the other hand, if the file pointer value jumps around as a function of time then the file access IO pattern is probably random. However, try looking closely at the file pointer plots since sometimes there is some underlying pattern giving it some sort of sequential pattern.
I think you might be surprised by your application profiling. You might find that applications do a fair amount of sequential IO. But just remember that production systems are running lots of applications that may be doing IO at the same time. As a consequence, the storage system may think it’s being hit with a bunch of random IO.
IOPS
A third aspect of IO patterns that people discuss is IOPS (I/O Operations per Second). People like to debate what an IO operation is, but I personally think of three IOPS metrics: (1) Read IOPS (read() operations per second), (2) Write IOPS (write() operations per second), and (3) Total IOPS (all IO operations per second). This last measure, total IOPS, takes into account reads, writes, and, in my opinion, any IO operation.
When testing storage hardware for IOPS, many times people define a read or write IOPS to be a 4KB data size because this is typically the smallest write or read function size that an OS produces. It is also the default buffer size for Linux glibc (look at stdio.h). But the 4KB size is not a standard by any stretch.
You will find vendors who run IOPS tests using 0KB size data sizes—that is, no data is actually written to or read from the disks. I’ve also seen vendors use 1 byte or 1 KB for data sizes.
Another frequent benchmark faux pas is to run one test that combines reads and writes in some ratio. A common one is something like 25 percent reads and 75 percent writes. The goal is to provide a single IOPS number for applications that do both reading and writing. It is a laudable goal, but it does make life very difficult in applying that performance measure to applications that don’t do IOPS in that ratio. This limits the usefulness of these measures.
Strace can provide IOPS pattern information. You simpye count the number of specific IO operations in a given second interval to get that information. This allows you to compute the Read IOPS, the Write IOPS, and the Total IOPS very easily.
Metadata—It’s Important Too
One other aspect of IO patterns that people almost always forget is the metadata function rate. Recall that metadata is data about the data and is a very important aspect of storage solution performance. In many ways it is like IOPS, but for metadata and not data (the number of metadata operations per second). Metadata rates are important because some applications can do a great deal of metadata operations during execution.
However, one question that gets debated is what is a metadata operation? Personally, I view a metadata operation as any IO operation that affects the metadata of a file in the file system. This includes any stat() operations, reading or writing data, file creations or removes, changing the dates or access permissions on the file, any readir() information, and so on. But the classic metadata rate metrics are: (1) file creates per second, (2) file removes per second, and (3) file stat() per second.
Again, strace can be your friend in this case. To get an idea of metadata function rates, you simply scan the strace file and count the number of specific metadata functions in a unit of time. These become your metadata rate metrics from the perspective of the application, adding to your IO pattern information.
Impact on Storage Design
If you can estimate all of the metrics I have mentioned so far, then you have the following list:
- Amount of time spent doing IO
- read/write function sizes
- read/write throughput
- Sequential or random file access
- IOPS (Read, Write, Total)
- Metadata rates (file creates, file removes, file stat() at a minimum)
This is quite a bit of information about the IO pattern of your application. Moreover, using all of the information in the strace of the application, you can also compute a very large amount of statistical measures of each of the IO pattern elements.
For example, you could plot a histogram of the read/write function sizes to understand the distribution of these functions. You can also compute the average, mean and mode of them to give you an understanding of the “typical” read/write size. Extending this a little further you can compute the standard deviation around the average, mean, and mode to understand how widely, or not, the function sizes are distributed.
There are other statistical measures that can give you an idea of the distribution of different metrics. Basically, you are trying to describe the IO pattern using the above metrics coupled with statistics. However, the real key is being able to understand and apply these metrics in designing or specifying a storage solution.
There is no science to being able to design a storage solution, even with a large number of statistics about the IO pattern of the application. But there are some general rules of thumb you can use.
A simple one is to check the peak IOPS for the application (read, write, and total). If the application seems to spend a fair amount of time doing IO and the IOPS are fairly large, then you will likely need a large number of hard drives to meet the IOPS requirements of the application. A really simple way to think of it is that a 7.2K SAS drive can roughly do 100 IOPS (it can actually do more but 100 is nice easy number to work with as a starting point). Therefore, divide your peak IOPS by 100 to find the number of drives you will need for the application. Given an individual drive capacity you can compute the overall capacity of the storage solution (don’t forget the RAID requirements which increases the number of drives).
If the overall solution capacity is too large, you can also choose to switch to SSD drives in place of the hard drives. But be sure that your application does quite a bit of IO and that it is IOPS driven before you start looking at SSDs as your storage media. Also, be sure to check that you can get enough capacity from the drives to satisfy your overall capacity requirements. I know of one application that had a very high peak IOPS (well over 100,000), which caused the user to start considering SSDs as the storage media. However, the application spent less than 3 percent of the total run time doing IO. Even if the SSDs had infinite performance, the application performance would have only increased by 3 percent. This is probably not a good application of SSDs, at least not a cost-effective one.
Overall the IO pattern information should be able to help the vendors understand how your application(s) do IO and what requirements they need to have to run effectively.
Vendor Impact
Vendors are on the receiving end of a great number of applications that supposedly do a great deal of IO. Based on these, they need to determine which applications should be tested or benchmarked on a given solution and, perhaps most importantly, what that solution configuration should look like (they can’t test every configuration).
Unfortunately, what many vendors have done is to create silly configurations to get the best TPC or SpecSFS scores. The configurations are ones that customers will never buy but the marketing siren call of having the best TPC or SpecSFS score is just too hard to resist. Therefore the vendors run what we call a hero benchmark (the best possible score regardless of the configuration). They run a hero benchmark, post the results, put out press releases, pat themselves on the back, high fives all around, then no one ever buys the configuration they tested.
I don’t really blame them because of the large number of possible IO patterns, but they have gone 180 degrees away from focusing on user applications to focusing on benchmarks that probably bear little resemblance to user applications. Moreover, the configurations they have tested will never be purchased by anyone because they bear little to no resemblance to what the applications need.
It is far better for you, the user, to take your IO pattern knowledge to the vendors and explain what you want tested. There may be options for using micro benchmarks to simulate some aspects of your IO patterns on standard test systems the vendors may have configured (don’t forget that it costs money to build and operate the test systems). Be prepared to work with the vendors to get the best tests possible on their solutions rather than throw a bunch of benchmarks at them see which vendor can complete the most tests (there are customers who routinely do this).
Furthermore, be sure to give the vendors enough time to run the tests and also try tuning the solution for the given tests. Not only does this help the vendors, it really helps you, the user. You get to see what options the vendors can provide which may or may not help the application better performance or the a lower solution cost (in other words—give them time and keep an open mind).
Summary
As you can tell, I usually like to finish my articles with a summary. For this article, the main point can be easily summarized: IO patterns help everyone—the users and the vendors. IO patterns help users understand how their application “do” IO allowing them to understand where there are potential bottlenecks and where there are potential opportunities for improving performance by changing applications. IO patterns help vendors because they have a much clearer view of what users want from their solution so they don’t have to run stupid, meaningless marketing benchmarks that have no meaning on configurations that no one will ever purchase.
Using simple tools, such as strace, allows you to get an idea of the IO patterns from the point of view of the application. It’s not too difficult to extract loads of useful information including the amount of time spent doing IO, read/write data sizes, sequential or random file access, throughput, IOPS, and metadata rates. All of this information helps you, the user, look for storage solutions that can possibly meet your requirements and it helps vendors hone in on solutions and configurations that can be proposed.
One last point I want to make is that I think that many people overlook the fact that the IO pattern information can also help developers perhaps redesign the IO portion of their application to improve performance. If the file access pattern is too random, perhaps there are some ways to change that to more a sequential access pattern so that they can take advantage of the throughput of the storage media. Or perhaps the read/write data sizes are too small, again penalizing the streaming performance of typical hard drives. This can be changed in the application improving overall performance.
Take at look at the IO patterns of your applications—you won’t be sorry.
?")

")
