

This is the first in a monthly series on storage and I/O related areas. Many of you might have read my two previous articles on file system issues and tapes. I believe starting at the beginning is important, so this month we will cover the start of how I/O works, beginning with the application.
Most people think that an understanding of I/O must begin with the hardware; I am of the opinion that just the contrary is true — as the storage hardware only takes the information that the application, operating system, file system and volume manager provides, and stores it. I believe that one needs to understand what the hardware is being told to do, and therefore one needs to understand what I call the whole data path. This data path includes the:
- Application,
- Operating System and tunables,
- File system and/or volume manager, and
- Storage hardware
Without a clear understanding of the application’s I/O requests patterns, and the various flavors of I/O passed to the operating system and below, an understanding of the I/O at the hardware layer is next to impossible. The reason is you will have no idea why the hardware behaves the way it does and why the I/O patterns look like they do. So for the next few months we will be discussing the I/O path to the hardware, followed by a discussion of the hardware itself. After that we will cover other areas related to storage, including evaluation and performance issues with associated hardware and software.
Page 2: The I/O Path
The I/O Path
Applications generally make requests to create files in one of at least two ways, both using POSIX standards calls.
- The file is created/opened with the open(2) system call, and I/O is made directly to the system via calls to the raw device, volume manager and/or file system using read(2), write(2), pread(2), pwrite(2) and/or the POSIX standard asynchronous I/O routines aio_read(3RT), aio_write(3RT), lio_listio(3RT).
- The file is created/opened with fopen(3) and I/O is done via the POSIX standard C library package (fread/fwrite/fprint). If a file is opened using fopen(3), the initial path through the system is different than when the file is opened using the open(2) system call. This method is typically used more often as it has fewer restrictions than using direct system calls.
Both of these methods work on UNIX, Windows, Linux and even mainframe systems as the POSIX standard is supported on all of them.
Using the C Library
With fopen(3), which uses the C library package (libc.a on UNIX and Linux systems), the data is moved from the user data space to a library buffer for each opened file. The C library is often called standard I/O. The size of this library buffer is by default:
| OS | Size in Bytes |
| Windows | 4096 (the range of values supported are from 2 to 32768 bytes) |
| Linux | 8192 |
| Solaris | 8192 |
| AIX | 4096 |
| SGI | 4096 |
Table 1. Buffer Sizes for Standard I/O
It should be noted that the actual memory size of the library buffer is really 8 bytes greater than the actual buffer size. These 8 bytes are used for pointer and control information for the buffer.
Page 3: Using the C Library (Continued)
By default, all requests made to the system will be the sizes listed in Table 1, regardless of the request size made from a fread(3), fwrite(3) and/or fprint(3) call. This is often called buffered I/O, as the I/O moves not from the user application space to the device but to the C library buffer first. This library buffer size can be changed by a call to the POSIX setvbuf(3). Sometimes making the buffer size over 128 KB (or in the Microsoft case, over 32 KB) does not ensure that the system will perform larger I/O because some operating systems and other software and hardware limitations do not allow those larger I/O requests.
Making the buffers bigger almost always improves performance when doing sequential I/O. When using open(2) and read/write system and/or asynchronous I/O ,the data bypasses the C library buffer that exists when using fopen(3). The request size is usually written in one system call, not withstanding the other software and hardware limitations.
The data path looks like this for buffered I/O:
ApplicationLibrary BufferOperation System CacheFile System/Volume ManagerDevice
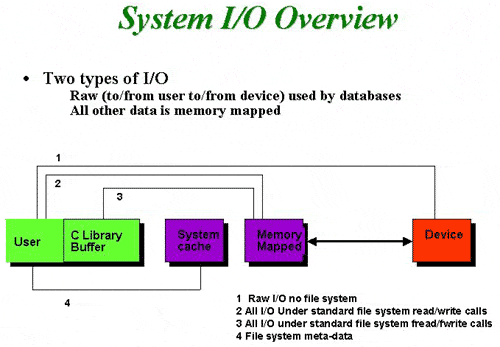
The data path for non-buffered I/O looks like:
Application Operation System Cache File System/Volume ManagerDevice
Sometimes the data moves from the C library buffer to the system cache and/or other file system caches or from the user system cache for systems calls. This is because if I/O is not read and/or written on disk hardware sector boundaries (currently multiples of 512 byte blocks on most disk drives), then the request is moved into the system cache to ensure that all I/O done to the system is on 512 byte boundaries.
As you will see in future columns, the amount of data moved does not always depend on the request size from the application or the library buffer, but sometimes depends on the file system instead.
Page 4: Why Does this Matter
Why Does this Matter
All of these issues are important because they affect the performance of the system, the CPU overhead and the performance of the underlying I/O system. In my second column I discussed the details on how I/O technology has changed over the last ~30 years and some of the hardware realities that are not really changeable.
Given the hardware realities, the bottom line is that you must either make large I/O requests to efficiently use the hardware or use many disk drives to allow for many disks to be performing an average seek and average latency for I/O requests.
Making Larger Requests
When using C library calls, you can change the size of your library buffer. This is accomplished by using the setvbuf(3) function after the file has been opened or created with the fopen(2) call. You must use setvbuf(3) after the file has been opened but before any read and/or writing to the file.
The library buffer size should be a multiple of 512 bytes and should be exactly 8 bytes more than that multiple of 512 bytes. (Note: Even though Microsoft supports buffer sizes smaller than 512 bytes, these sizes should only be used for devices with smaller physical hardware units. Most current disks support 512 bytes.) The 8 bytes are required for the hash table for each library buffer and, if not used, will significantly reduce your I/O performance and increase your system overhead for I/O as the I/O is not being done on 512 byte boundaries (hardware sector).
For example, if you want to set your library buffer size to 64 KB, you would set it to:
buffer_size=(64*1024)+8;
The following example shows how to use setvbuf(3) with a 256 KB buffer:
#include
main ()
{
char *buf;
FILE *fp;
fp = fopen ("data.fil", "r");
buf = valloc (262144);
setvbuf (fp, buf, _IOFBF, 262144+8);
fclose(fp);
}
Page 5: Making Larger Requests (Continued)
As mentioned, if the 8 bytes are not added, this will cause poor performance. For each write request the system will have to read-modify write. Read-modify-write happens when the requests do not begin and end on 512 byte boundaries. Each time data is written, the system will have to read the data into the system buffers, and then the system will write the data from the user space to the system buffers such that it is written on 512 byte boundaries, and then data is written from the system buffers to the device.
The rule is that all I/O must be done on physical hardware boundaries — you either provide it to the hardware, or it must be done in software. This will happen for each write, which significantly increases system overhead and dramatically reduces I/O performance.
So for programs using fopen/fread/fwrite, making larger I/O requests is easy if you have access to the source code. The real question is how to determine the optimal library buffer size. My rule of thumb for sequential I/O is to make the library buffer size at least 4 times the size of the fread(3) and/or fwrite(3) request size. If you can afford the memory usage, the library buffer size should be a much larger multiple in the range of 512 KB to 16 MB.
Determining the correct size has a great deal to do with the rest of the I/O path including the operating system, file system, volume manager, and storage hardware. Ascertaining the exact optimal value will have to wait until a later article, but making it large will immediately improve performance over using the default. Of course, this only works for files for which you are performing a great deal of I/O.
If you have an application which does a large amount of random I/O, making the buffer larger than the I/O request will hurt performance, as you will read data into the buffer that you will not end up using. The only time making the buffer larger than the request is helpful is when you can fit the entire file into the library buffer. Sometimes for older applications where memory is at a premium, the whole file could be placed into memory by using a large library buffer.
Conclusions
The real issue is that you will need to match the application I/O efficiency with the amount of storage necessary. If you have an application requirement of 190 MB/sec for reading and writing and the application makes 1 KB random I/O requests, the amount of hardware needed to support that requirement is much greater (likely 10x greater) than if the application makes 16 MB sequential I/O requests.
What I plan to address over the next months is the whole I/O path and issues with performance and tuning for the server hardware, operating system, file system/volume manager, HBA, FC devices (such as tape and disk), and applications (such as databases).
» See All Articles by Columnist Henry Newman
