


It’s a fairly well known fact that solid state disk (SSD) performance can suffer over time. This was quite common in early SSDs, but newer controllers have helped reduce this problem through a variety of techniques. In the second part of this two-part article examining performance degradation in SSDs, the rubber meets the road as we perform some benchmarking of an enterprise class SSD to understand performance before the drive is heavily used, and after.
Review of SSD Performance Issues
In the first part of this article, we examined some of the origins of SSD performance problems. The nature of the design of floating gate transistors, the design of the underlying NAND chips, and the design of the SSDs are the source of the performance degradation problems as well as the performance benefits of SSDs.
In reviewing how SSDs are constructed, remember that SSDs are erased in units of blocks that are typically about 512KB in size, meaning that if a single page (4KB) on a particular block is changed, then the entire SSD has to be reprogrammed (rewritten). The reprogramming process uses a slow cycle of read-modify-erase-write. That is, all of the data on the particular block first has to be read, typically into cache, then the modified data is merged with the cached data, then the particular SSD block has to be erased, and finally, the updated block is written to the freshly erased block.
One would think that this cycle wouldn’t take too long since SSDs are very fast storage devices with no moving parts. However, the performance of SSDs is asymmetric with erasing being several orders of magnitude slower than reading, and writing being almost an order of magnitude slower than reading. This leads to a very slow read-modify-erase-write cycle that severely penalizes an otherwise extremely fast storage media.
Even worse, the read-modify-erase-write cycle leads to something called write amplification. This refers to the fact that a simple change or update to a page inside a block leads to additional write cycles being used. The number of writes that have to occur to write a particular chunk of data to the storage media has a value of 1 when no additional writes are needed (this is typical for hard drives). A larger value means that more than one write has to happen to write the data to the storage media. This measure of the number of writes to actually write a chunk of data is commonly the “write amplification factor” and early SSDs had a very large value (larger than 1). However, don’t forget that SSDs have limited write cycles (Single Level Cell (SLC) has approximately 100,000 cycles and Multi Level Cell (MLC) has approximately 10,000), so write amplification factors greater than 1 prematurely age an SSD (i.e. use the write cycles faster than they should).
Solid state disk manufacturers and vendors have known about these problems for some time and have developed several techniques to improve their performance in light of their limitations as well as reduce write amplification which can reduce the life of an SSD.
One technique is called Write Combining where multiple writes are collected by the controller before being written to the block(s) within the SSD. The goal is to combine several small writes into a single larger write with the hope that neighboring pages of data are likely to be changed at the same time, and that these pages really belong to the same file. It can greatly reduce the write amplification factor improving the write performance, but it depends upon how the data is sent to the drive and whether the data chunks are part of the same file, or are likely to be changed/erased at the same time.
Another technique, called Over-Provisioning, keeps a certain number of blocks in reserve and doesn’t expose them to the OS. For example, if the SSD has a total of 75GB of total space, perhaps only 60GB of it will be exposed to the OS. These reserved blocks can be used for the general pool of available blocks, without the knowledge of the OS, to help performance. These “extra” blocks increase the size of the block pool guaranteeing that at no time will the pool have zero available blank blocks creating a bottleneck while the application waits for a read-modify-erase-write cycle to happen before actually writing data to the SSD. This concept also has benefits for longevity because if a particular block has fewer write cycles remaining compared to any other block, then it can be switched with a block in the reserved pool that has much less usage. This helps the overall wear-leveling of the SSD.
A third technique that has been eagerly awaited for some time is something called a TRIM command. Recall that one of the big performance problems is that when a write is performed to a page that has not been erased yet, the entire block that contains that page has to be read into cache, the new data is merged with the existing data in the block, the block on the SSD is erased, which takes quite a bit of time, and the new block in cache is written to the block. This read-modify-erase-write process takes much more time than just a write would on the SSD. The TRIM command tells the SSD controller when a page is no longer needed so that it can be flagged for erasing. Then the SSD controller can write the new data to a “clean” page on a block so that the entire read-modify-erase-write cycle is avoided (the cycle just becomes “write”). Thus, the overall write performance is much better.
All of these techniques, plus others, have been incorporated into SSDs with varying degrees of success. As with everything, there are trade-off that have to be made in the design of the SSD. These previously described techniques require a more sophisticated controller which costs more to design and manufacture. Over-provisioning means that you don’t get to use the entire capacity of the drive increasing the apparent cost of the drive. So SSD manufacturers combine these various techniques while watching the overall performance and price when they design a new SSD.
In this second part of the article series, I want to test an enterprise class drive, an Intel X25-E drive, to see how well it performs over time as a way to understand the impact of these techniques on SSD performance. In particular, I will be performing some benchmarks on a brand new clean drive and then running some I/O intensive tests against the drive. Immediately following the I/O tests I will re-run the benchmarks to look for signs of degraded performance.
Benchmarking Approach and Setup
The old phrase of “if you’re going to do it, do it right,” definitely rings true for benchmarking. All too often, storage benchmarks are nothing less than marketing materials providing very little useful information. So in this article I will follow the concepts explained in this article that should improve the quality of the benchmarks. In particular I will follow this advice.
- The motivation behind the benchmarks will be explained (if it hasn’t already)
- Relevant and useful storage benchmarks will be used
- The benchmarks will be detailed as much as possible
- The tests will run for more than 60 seconds
- Each test is run 10 times and the average and standard deviation of the results is reported
These basic steps and techniques can make benchmarking much more useful.
Page 2: Fixing SSD Performance Degradation, Part 2
Back to Page 1
The benchmarks in this article are designed to explore the impact of performance enhancement techniques on SSD performance over time. Specifically, I want to perform an initial set of benchmarks on an SSD, then torture it with some intensive I/O workloads, and then rerun the benchmarks and examine the differences. Before starting the test I do not know what the differences in performance will be but I do anticipate seeing some differences if, for no other reason, there will be some impact from the file system and any fragmentation caused by the testing.
The highlights of the system used in the testing are below:
- GigaByte MAA78GM-US2H motherboard
- An AMD Phenom II X4 920 CPU
- 8GB of memory (DDR2-800)
- Linux 2.6.34 kernel (with bcache patches only)
- The OS and boot drive are on an IBM DTLA-307020 (20GB drive at Ultra ATA/100)
- /home is on a Seagate ST1360827AS
- Two drives used for storing scratch data are Seagate ST3500641AS-RK with 16 MB cache each. These are /dev/sdb and /dev/sdc.
- Single Intel X25-E SLC disk (64GB) connected to a single SATA port (this is presented as /dev/sdd).
I used CentOS 5.4 on this system but I used my own kernel – 2.6.34 with some patches (which will be referred to as 2.6.34+ in the rest of this article). The 2.6.34 kernel was selected because it supports the TRIM command. Also, ext4 will be used as the file system since it also supports TRIM as well. The details of creating the ext4 file system are important since they are tailored for SSDs and are discussed in the following sub-section.
Building ext4
In researching options for building ext4 on an SSD, a blog from the primary maintainer of ext4 was found. Theodore Ts’o’ blog discusses how he formatted ext4 for an Intel SSD. The first step was to partition the SSD to align partitions on 128KB boundaries (following Theodore’s advice). This is accomplished by the common fdisk command:
[root@test64 ~]# fdisk -H 224 -S 56 /dev/sddwhere the -H option is the number of “heads” and the -S option is the number of sectors per track. Don’t forget that fdisk still thinks of everything like a spinning disk so while these options perhaps don’t make any sense for an SSD. But aligning the partitions on 128KB boundaries is important for best performance. As recommend by Theodore, I used the following command for creating the ext4 file system.
[root@test64 ~]# mke2fs -t ext4 -E stripe-width=32 resize=500G /dev/sdd1The first option “stripe-width=32” was recommended as a way to improve performance and the second option “resize=500G” is used to reduce any wasted space in anticipation of growing the file system beyond 500GB’s. Notice that I let ext4 select the journal size it on the SSD.
Benchmarks
I chose to test three aspects of the SSD (and file system):
- Throughput
- IOPS
- Metadata
The first test stresses the bandwidth capability of the SSD while the second test stresses the ability to service I/O requests as quickly as possible (an often underestimated aspect of storage performance). The third test is more focused on the file system but it also measures the performance of the underlying storage device because it has to service the file system data requests as quickly as possible. Consequently, it is more related to IOPS in terms of a performance measure, but it will give us some insight into the performance of the file system on the storage device which could give us additional information on the performance of the SSD.
The benchmarks selected are IOzone for measuring both throughput and IOPS and metarates for measuring metadata performance.
IOzone
IOzone is one of the most popular throughput benchmarks partly because it is open-source and is written in very plain ANSI C (not an insult but a compliment), and perhaps more importantly, it tests different I/O patterns which very few benchmarks actually do. It is capable of single thread, multi-threaded, and multi-client testing. The basic concept of IOzone is to break up a file of a given size into records. Records are written or read in some fashion until the file size is reached. Using this concept, IOzone has a number of tests that can be performed. The tests used in this article are:
- Write
This is a fairly simple test that simulates writing to a new file. Because of the need to create new metadata for the file, many times the writing of a new file can be slower than rewriting to an existing file. The file is written using records of a specific length (either specified by the user or chosen automatically by IOzone) until the total file length has been reached. - Re-write
This test is similar to the write test but measures the performance of writing to a file that already exists. Since the file already exists and the metadata is present, it is commonly expected for the re-write performance to be greater than the write performance. This particular test opens the file, puts the file pointer at the beginning of the file, and then writes to the open file descriptor using records of a specified length until the total file size is reached. Then it closes the file which updates the metadata. - Read
This test reads an existing file. It reads the entire file, one record at a time. - Re-read
This test reads a file that was recently read. This test is useful because operating systems and file systems will maintain parts of a recently read file in cache. Consequently, re-read performance should be better than read performance because of the cache effects. However, sometimes the cache effect can be mitigated by making the file much larger than the amount of memory in the system. - Random Read
This test reads a file with the accesses being made to random locations within the file. The reads are done in record units until the total reads are the size of the file. The performance of this test is impacted by many factors including the OS cache(s), the number of disks and their configuration, disk seek latency, and disk cache among others. - Random Write
The random write test measures the performance when writing a file with the accesses being made to random locations with the file. The file is opened to the total file size and then the data is written in record sizes to random locations within the file. - Backwards Read
This is a unique file system test that reads a file backwards. There are several applications, notably, MSC Nastran, that read files backwards. There are some file systems and even OS’s that can detect this type of access pattern and enhance the performance of the access. In this test a file is opened and the file pointer is moved 1 record forward and then the file is read backward one record. Then the file pointer is moved 2 records backward in the file, and the process continues. - Record Rewrite
This test measures the performance when writing and re-writing a particular spot with a file. The test is interesting because it can highlight “hot spot” capabilities within a file system and/or an OS. If the spot is small enough to fit into the various cache sizes; CPU data cache, TLB, OS cache, file system cache, etc., then the performance will be very good. - Strided Read
This test reads a file in what is called a strided manner. For example, you could read at a file offset of zero for a length of 4 Kbytes, then seek 200 Kbytes forward, then read for 4 Kbytes, then seek 200 Kbytes, and so on. The constant pattern is important and the “distance” between the reads is called the stride (in this case it is 200 Kbytes). This access pattern is used by many applications that are reading certain data structures. This test can highlight interesting issues in file systems and storage because the stride could cause the data to miss any striping in a RAID configuration, resulting in poor performance. - fwrite
This test measures the performance of writing a file using a library function “fwrite()”. It is a binary stream function (examine the man pages on your system to learn more). Equally important, the routine performs a buffered write operation. This buffer is in user space (i.e. not part of the system caches). This test is performed with a record length buffer being created in a user-space buffer and then written to the file. This is repeated until the entire file is created. This test is similar to the “write” test in that it creates a new file, possibly stressing the metadata performance. - frewrite
This test is similar to the “rewrite” test but using the fwrite() library function. Ideally the performance should be better than “Fwrite” because it uses an existing file so the metadata performance is not stressed in this case. - fread
This is a test that uses the fread() library function to read a file. It opens a file, and reads it in record lengths into a buffer that is in user space. This continues until the entire file is read. - freread
This test is similar to the “reread” test but uses the “fread()” library function. It reads a recently read file which may allow file system or OS cache buffers to be used, improving performance.
There are other options that can be tested, but for this exploration only the previously mentioned tests will be examined. However, even this list of tests is fairly extensive and covers a large number of application access patterns that you are likely to see (but not all of them).
Page3: Fixing SSD Performance Degradation, Part 2
For IOzone the system specifications are fairly important since they affect the command line options. In particular, the amount of system memory is important because this can have a large impact on the caching effects. If the problem sizes are small enough to fit into the system or file system cache (or at least partially), it can skew the results. Comparing the results of one system where the cache effects are fairly prominent to a system where cache effects are not conspicuous, is comparing the proverbial apples to oranges. For example, if you run the same problem size on a system with 1GB of memory versus a system with 8GB you will get much different results.
For this article, cache effects will be limited as much as possible. Cache effects can’t be eliminated entirely without running extremely large problems and forcing the OS to virtually eliminate all caches. But, one of the best ways to minimize the cache effects is to make the file size much bigger than the main memory. For this article, the file size is chosen to be 16GB which is twice the size of main memory. This is chosen arbitrarily based on experience and some urban legends floating around the Internet.
For this article, the total file size was fixed at 16GB and four record sizes were tested: (1) 1MB, (2) 4MB, (3) 8MB, and (4) 16MB. For a file size of 16GB that is (1) 16,000 records, (2) 4,000 records, (3) 2,000 records, (4) 1,000 records. Smaller record sizes took too long to run since they number of records would be very large so they are not used in this article.
The command line for the first record size (1MB) is,
./IOzone -Rb spreadsheet_output_1M.wks -s 16G -r 1M > output_1M.txtThe command line for the second record size (4MB) is,
./IOzone -Rb spreadsheet_output_4M.wks -s 16G -r 4M > output_4M.txtThe command line for the third record size (8MB) is,
./IOzone -Rb spreadsheet_output_8M.wks -s 16G -r 8M > output_8M.txtThe command line for the fourth record size (16MB) is,
./IOzone -Rb spreadsheet_output_16M.wks -s 16G -r 16M > output_16M.txt
IOPS Using IOzone
For measuring IOPS performance I’m also going to also use IOzone. While IOzone is more commonly used for measuring throughput performance, it can also measure operations per second (IOPS – IO Operations Per Second) with a simple command line option. More specifically, it can be used to measure sequential read and write IOPS as well as random read and random write IOPS.
For this article, IOzone was used to run four specific IOPS tests. These tests are:
- Write
- Read
- Random Read
- Random Write
As with the throughput tests, the IOPS tests used a file size that is twice the size of memory. The goal is to push the file size out of what could be cached by Linux.
For this article a total file size of 16GB was used. Within this 16GB file size, four record sizes are tested: (1) 4KB, (2) 8KB, (3) 32KB, and (4) 64KB record sizes. These sizes were chosen because the run times for smaller record sizes were much longer and using our good benchmarking skills of running each test 10 times, resulted in very long benchmark times (weeks). In addition, 4KB is the typical record size used in IOPS testing.
You might laugh at the larger record sizes, but there are likely to be applications that depend upon how quickly they can read/write 64KB records (I quit saying “never” with respect to application I/O – I’ve seen some truly bizarre patterns so “never” has been removed from vocabulary.).
The command line for the first record size (4KB) is,
./iozone -Rb spreadsheet_output_4K.wks -O -i 0 -i 1 -i 2 -e -+n -r 4K -s 16G > output_4K.txtThe command line for the second record size (8KB) is,
./iozone -Rb spreadsheet_output_8K.wks -O -i 0 -i 1 -i 2 -e -+n -r 8K -s 16G > output_8K.txtThe command line for the third record size (32KB) is,
./iozone -Rb spreadsheet_output_32K.wks -O -i 0 -i 1 -i 2 -e -+n -r 32K -s 16G > output_32K.txtThe command line for the fourth record size (64KB) is,
./iozone -Rb spreadsheet_output_64K.wks -O -i 0 -i 1 -i 2 -e -+n -r 64K -s 16G > output_64K.txt
Metarates
A common benchmark used for HPC storage systems is called metarates. Metarates was developed by the University Corporation for Atmospheric Research (UCAR) and is a MPI application that tests metadata performance by using POSIX system calls:
- creat() – open and possibly create a file
- stat() – get file status
- unlink() – delete a name and possibly the file it refers to
- fsync() – synchronize a file’s in-core state with storage device
- close() – close a file descriptor
- utime() – change file last access and modification times
Using these system calls, the main analysis options for metarates are the following:
- Measure the rate of file creates/closes (file creates/closes per second)
- Measure the rate of utime calls (utime operations per second)
- Measure the rate of stat calls (stat operations per second)
Metarates has options for the number of files to write per MPI process (remember that you will have N processes with a MPI application where N is a minimum of 1) and if the files are to be written to a single directory or to many directories. It also has the option of using the system call fsync() to synchronize the file’s in-core state with the storage device.
Remember that Metarates is an MPI application allowing us to choose the number of processes (cores) we use during the run. So for this benchmark and this test system, 1, 2, and 4 cores were used (three independent tests). These tests are labeled as NP=1 (1 core), NP=2 (2 cores), NP=4 (4 cores) where NP stands for Number of Processes.
Not forgetting our good benchmarking skills, the run time (wall clock time) of the runs should be greater than 60 seconds if possible. So the number of files was varied for 4 MPI processes until a run time of 60 seconds was reached. The resulting number of files from the test was found to be 1,000,000 and was fixed for all tests. Also it was arbitrarily decided to have all files are written to the same directory with the goal of really stressing the metadata performance and, hopefully, the SSD.
The final command line used for metarates for all three numbers of processors (1, 2, and 4) is the following.
time mpirun -machinefile ./machinefile -np 4 ./metarates -d junk -n 1000000 -C -U -S -u >> metarates_disk.np_4.1.outwhere the “-np” option stands for number of processes (in this case 4), “-machinefile” refers to the list of hostnames of systems to be used in the run (in this case it is a file name “./machinefile” that contains the test machine hostname repeated 4 times – once for each process), and the results to stdout are sent to a file “metarates_disk.np_4.1.out” which is an example of how the output files were named.
Notice that three different performance measures are used:
- File create and close rate (how many per second)
- File stat rate (how many “stat” operations per second)
- File utime rate (how many “utime” operations per second)
Testing Process
As mentioned earlier in the article, the basic testing process runs the benchmarks on a “clean” drive that is brand-new, followed by some heavy I/O tests on the drive, and then immediately the same set of benchmarks are run and compared to the first set of benchmarks. The set of benchmarks has already been discussed but the “torture” tests need to also be discussed.
The goal of the I/O intensive tests is to exercise the underlying storage media but this also means that the file system needs to be exercised. In particular, we want to stress the Intel SSD and then retest it to see how the various performance technologies help improve performance. So these I/O intensive tests should run both smaller and larger files as well as various record sizes. They should also stress the storage performance as much as possible to put the SSD controller under as much pressure as possible (this can help put block allocation techniques under pressure). The application chosen is IOR.
IOR is an MPI based I/O benchmark code designed to test both N-N (N clients reading/writing to N files) as well as N-1 performance (N clients all reading/writing to a single file). IOR has many, many options depending upon what you want to test but the basic approach is to break up the file into what are called segments. The segments are in turn broken into blocks. The data for each block is transferred in “t” size units (t = transfer size). Figure 1 below from a presentation by Hongzhang Shan and John Shalf from NERSC, shows how a file is constructed from these parameters.
Figure 1 – IOR File Layout
In this simple illustration, the segment size and the block size are the same (i.e. one block per segment).
Two IOR runs were made and each of these was repeated 10 times. The first IOR command line is:
mpirun -np 4 -machinefile ./machinefile ./IOR -a POSIX -b 64k -F -i 10 -s 200000 -t 4k -vvThe first part of the command, “mpirun -np 4 -machinefile ./machinefile” is all MPI command options:
- -np 4: This means that we are using 4 processes for this run (remember that IOR is an MPI code) which corresponds to 4 cores in the system.
- -machinefile ./machinefile: This tells MPI the location of the list of hostnames to use during the run. Since this is a single system, the file just lists the system hostname four times.
- ./IOR: This is the name of the executable
The IOR run options come after the executable IOR. These options are explained below:
- -a POSIX: This tells IOR to use the POSIX API (not MPI-IO or other API’s)
- -b 64k: This option is the block size which in this case is 64KB.
- -F: This tells IOR to use 1 file per process. For this example since we have 4 processes, we will get 4 files (this is what is referred to as N-N I/O or N processes creating a total of N files).
- -i 10: This option tells IOR to run the test 10 times. This is the number of repetitions IOR itself will run during the test. However I will still run the IOR command 10 times.
- -s 200000: This tells IOR the the number of segments to use. In this case it is 200,000.
- -t 4k: This tells IOR the transfer size which in this case is 4KB.
- -vv: This option tells IOR to be fairly verbose with it’s output.
IOR will run both a read and a write test with the previous options presented. You can calculate the size of the files based on block size, the number of blocks per segment, and the number of segments. However, it is easier just to show you the output from a single run of IOR with the specific options:
*** IOR test runs: Date stated *** Tue Sep 28 09:13:35 EDT 2010
*** Run 1 *** Tue Sep 28 09:13:35 EDT 2010
IOR-2.10.2: MPI Coordinated Test of Parallel I/O
Run began: Tue Sep 28 09:13:37 2010
Command line used: ./IOR -a POSIX -b 64k -F -i 10 -s 200000 -t 4k -vv
Machine: Linux test64 2.6.30 #5 SMP Sat Jun 12 13:02:20 EDT 2010 x86_64
Using synchronized MPI timer
Start time skew across all tasks: 0.05 sec
Path: /mnt/home1/laytonjb
FS: 58.7 GiB Used FS: 0.2% Inodes: 3.7 Mi Used Inodes: 0.0%
Participating tasks: 4
task 0 on test64
task 1 on test64
task 2 on test64
task 3 on test64
Summary:
api = POSIX
test filename = testFile
access = file-per-process
pattern = strided (200000 segments)
ordering in a file = sequential offsets
ordering inter file= no tasks offsets
clients = 4 (4 per node)
repetitions = 10
xfersize = 4096 bytes
blocksize = 65536 bytes
aggregate filesize = 48.83 GiB
Using Time Stamp 1285679617 (0x4ca1ea01) for Data Signaturev
Commencing write performance test.
Tue Sep 28 09:13:37 2010
access bw(MiB/s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---------- --------- -------- -------- -------- -------- ----
write 198.23 64.00 4.00 0.049995 252.24 2.23 252.24 0 XXCEL
[RANK 000] open for reading file testFile.00000000 XXCEL
Commencing read performance test.
Tue Sep 28 09:17:49 2010
read 241.51 64.00 4.00 0.046069 207.03 3.40 207.03 0 XXCEL
Using Time Stamp 1285680083 (0x4ca1ebd3) for Data Signature
Commencing write performance test.
Tue Sep 28 09:21:23 2010
...
Operation Max (MiB) Min (MiB) Mean (MiB) Std Dev Max (OPs) Min (OPs) Mean (OPs) Std Dev Mean (s)Op grep #Tasks tPN reps fPP reord reordoff reordrand seed segcnt blksiz xsize aggsize
--------- --------- --------- ---------- ------- --------- --------- ---------- ------- -------
write 198.43 197.84 198.19 0.17 0.25 0.25 0.25 0.00 252.28032 4 4 10 1 0 1 0 0 200000 65536 4096 52428800000 -1 POSIX EXCEL
read 242.43 240.65 241.78 0.47 0.31 0.31 0.31 0.00 206.79841 4 4 10 1 0 1 0 0 200000 65536 4096 52428800000 -1 POSIX EXCEL
Max Write: 198.43 MiB/sec (208.07 MB/sec)
Max Read: 242.43 MiB/sec (254.20 MB/sec)
Run finished: Tue Sep 28 10:31:01 2010From the output you can see that the aggregate file size is 48.83 GiB (remember we have to keep the file size under 64GB since that is the size of the drive and 58.7 GiB is the size of the formatted file system). In some early testing, this IOR command took about 7 minutes to run on the test system.
The second IOR command line is very similar to the first but with different block size, transfer size, and number of segments. The command line is
mpirun -np 4 -machinefile ./machinefile ./IOR -a POSIX -b 1M -F -i 10 -s 14000 -t 256k -vvThe output from this IOR run is,
IOR-2.10.2: MPI Coordinated Test of Parallel I/O
Run began: Tue Sep 28 10:31:03 2010
Command line used: ./IOR -a POSIX -b 1M -F -i 10 -s 14000 -t 256k -vv
Machine: Linux test64 2.6.30 #5 SMP Sat Jun 12 13:02:20 EDT 2010 x86_64
Using synchronized MPI timer
Start time skew across all tasks: 0.00 sec
Path: /mnt/home1/laytonjb
FS: 58.7 GiB Used FS: 0.2% Inodes: 3.7 Mi Used Inodes: 0.0%
Participating tasks: 4
task 0 on test64
task 1 on test64
task 2 on test64
task 3 on test64
Summary:
api = POSIX
test filename = testFile
access = file-per-process
pattern = strided (14000 segments)
ordering in a file = sequential offsets
ordering inter file= no tasks offsets
clients = 4 (4 per node)
repetitions = 10
xfersize = 262144 bytes
blocksize = 1 MiB
aggregate filesize = 54.69 GiB
Using Time Stamp 1285684263 (0x4ca1fc27) for Data Signature
Commencing write performance test.
Tue Sep 28 10:31:03 2010
access bw(MiB/s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---------- --------- -------- -------- -------- -------- ----
write 197.90 1024.00 256.00 0.000222 282.96 1.02 282.96 0 XXCEL
[RANK 000] open for reading file testFile.00000000 XXCEL
Commencing read performance test.
Tue Sep 28 10:35:46 2010
read 241.42 1024.00 256.00 0.000369 231.97 6.03 231.97 0 XXCEL
Using Time Stamp 1285684785 (0x4ca1fe31) for Data Signature
Commencing write performance test.
Tue Sep 28 10:39:45 2010
...
Operation Max (MiB) Min (MiB) Mean (MiB) Std Dev Max (OPs) Min (OPs) Mean (OPs) Std Dev Mean (s)Op grep #Tasks tPN reps fPP reord reordoff reordrand seed segcnt blksiz xsize aggsize
--------- --------- --------- ---------- ------- --------- --------- ---------- ------- -------
write 197.95 197.68 197.79 0.09 0.06 0.06 0.06 0.00 283.12821 4 4 10 1 0 1 0 0 14000 1048576 262144 58720256000 -1 POSIX EXCEL
read 242.10 241.06 241.56 0.31 0.07 0.07 0.07 0.00 231.82731 4 4 10 1 0 1 0 0 14000 1048576 262144 58720256000 -1 POSIX EXCEL
Max Write: 197.95 MiB/sec (207.56 MB/sec)
Max Read: 242.10 MiB/sec (253.86 MB/sec)
Run finished: Tue Sep 28 11:57:59 2010This IOR test uses a slightly larger file size of 54.69 GiB. It also takes about 90 minutes for this test to finish.
These two IOR command lines were run 10 times each as the I/O intensive benchmark for the SSD. Notice that the file sizes are quite large to put maximum pressure on the drive and the block sizes are both small and large to put even more pressure on the SSD and it’s controller.
Results
With the explanation of the benchmarks behind us, let’s move on to the meat of the article – the results.
Page 4: Fixing SSD Performance Degradation, Part 2
All of the results are presented in bar chart form with the average values plotted and the standard deviation shown as error bars. For each test there are two bars plotted – “before” and “after”. The “before” results are the initial benchmarks of the SSD before it was stressed by using IOR. The “after” results are the benchmark results after the device was stressed. We are looking for noticeable differences in the “before” and “after” results.
There will be three sections of results: (1) Throughput (performed using IOzone), (2) IOPS (also performed using IOzone), and (3) Metadata (performed using metarates).
Throughput Results
The first throughput result is for the write throughput test. Figure 2 below presents the results.
Figure 2 – Write Throughput Results from IOzone in KB/s
You can see that for three of the record sizes, the write throughput performance was slightly better after the I/O intensive tests were run (average values). However, you have to pay very close attention to the standard deviation. If the differences of the two tests falls within the standard deviations then it is impossible to say that “after” is better than “before.”
For example, for a record size of 1MB, one might think that the “after” results are better than the “before” results. However, the difference between the two tests falls inside the standard deviation, making it impossible to say with reasonably certainty that “after” is faster than “before”.
Figure 3 below presents the results for the second test – the re-write throughput results.
Figure 3 – Re-write Throughput Results from IOzone in KB/s
For the re-write throughput benchmark, at a 4MB record size, it appears that the “before” results are a bit faster than the “after” results. The difference is fairly small however – about 3.5%. For the other record sizes, the re-write performance difference between before the stress testing and after, fall in the standard deviation or are so small that the difference is really minor.
Figure 4 below presents the read throughput results.
Figure 4 – Read Throughput Results from IOzone in KB/s
Despite the appearance that the “before” results are better than the “after” results, the differences are within the standard deviation so it is impossible to conclusively say that “before” is better than “after” for this test.
Figure 5 below presents the re-read throughput results.
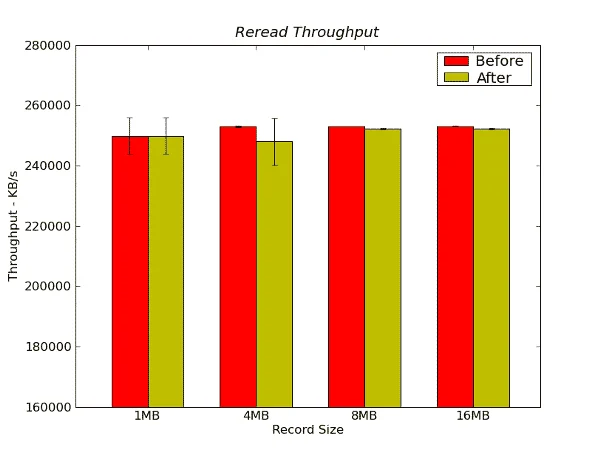
Figure 5 – Re-Read Throughput Results from IOzone in KB/s
For this test, we don’t see much difference in performance between the “before” and “after” benchmarks.
Figure 6 below presents the random read throughput results.
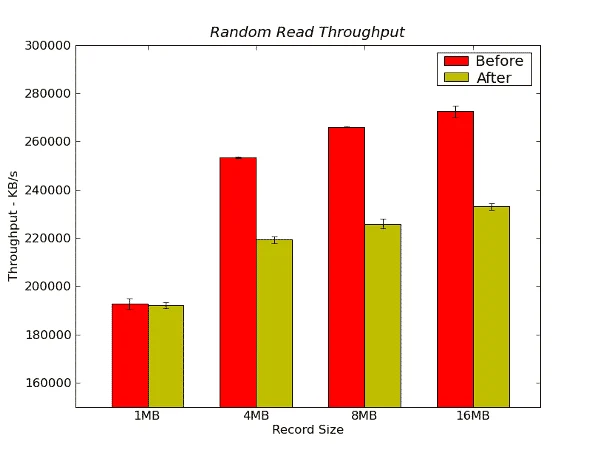
Figure 6 – Random Read Throughput Results from IOzone in KB/s
In this test we actually see quite a bit of difference between the tests. The “before” performance is much better than the “after” performance. For record sizes of 4MB, 8MB, and 16MB, the difference is about 13-15% in favor of the “before” results (this is average performance).
Figure 7 below presents the random write throughput results.
Figure 7 – Random Write Throughput Results from IOzone in KB/s
These test results are a bit different than the random read tests. At a record size of 4MB, the performance before the stress test (“before”) was quite a bit better than “after” the stress test (a bit over 20%). But at the other record sizes the “before” and “after” performance appear to be within the standard deviation of each other. Consequently, it’s impossible to say that one is better than the other.
Figure 8 below presents the backwards read throughput results.
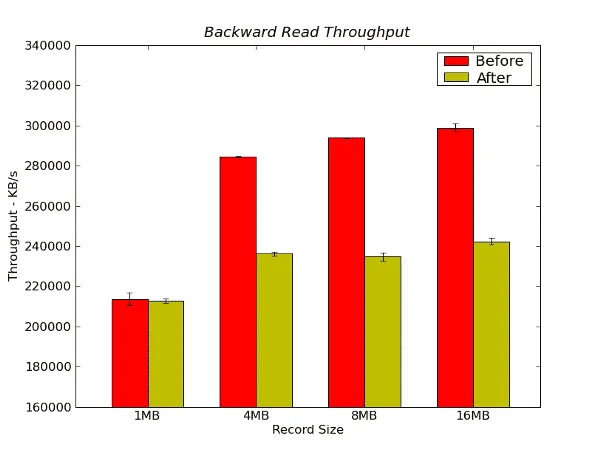
Figure 8 – Backwards Read Throughput Results from IOzone in KB/s
For the three largest record sizes the performance prior to the stress test is much better than after. The difference is about 17-20%. However, this I/O pattern is rather unique to a small set of applications but you do see this pattern in some important HPC applications.
Figure 9 below presents the record rewrite throughput results.
Figure 9 – Record Rewrite Throughput Results from IOzone in KB/s
The performance before the stress testing and after are about the same for this particular benchmark.
Figure 10 below presents the strided read throughput results.
Figure 10 – Strided Read Throughput Results from IOzone in KB/s
For this particular I/O pattern we see that the performance prior to the stress test is quite good compared to after, particularly for the largest three record sizes. In general the “before” results are about 22-23% better than the “after” results.
Figure 11 below presents the fwrite throughput results.
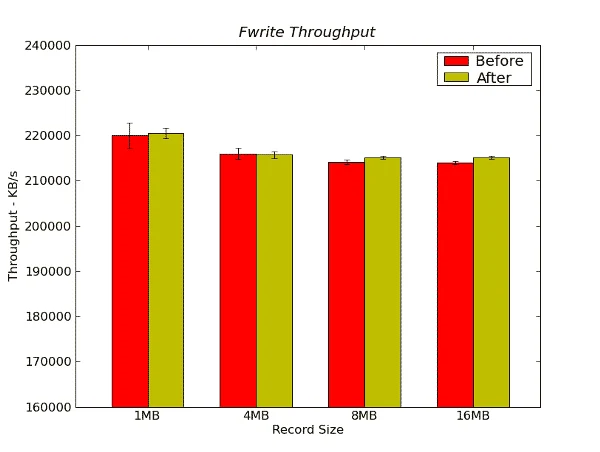
Figure 11 – Fwrite Throughput Results from IOzone in KB/s
For this test there is very little difference between the performance before or after the stress test.
Figure 12 below presents the frewrite throughput results.
Figure 12 – Frewrite Throughput Results from IOzone in KB/s
As with the fwrite results there is very little difference between the performance before or after the stress test.
Figure 13 below presents the fread throughput results.
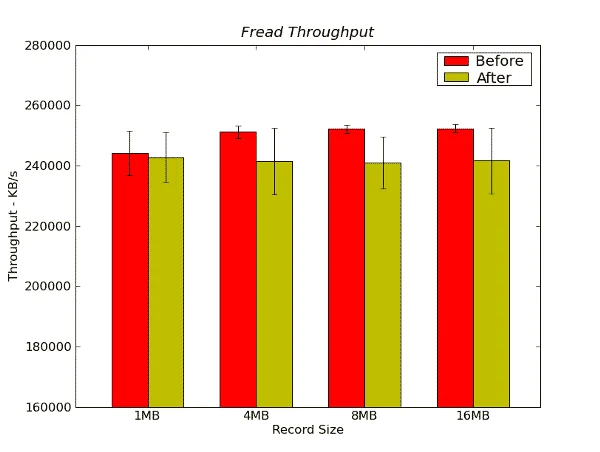
Figure 13 – Fread Throughput Results from IOzone in KB/s
There is some difference in the averages for the the “before” and “after” performance but they are within the standard deviation of the results so it is impossible to say that one is better than the other.
Figure 14 below presents the freread throughput results.
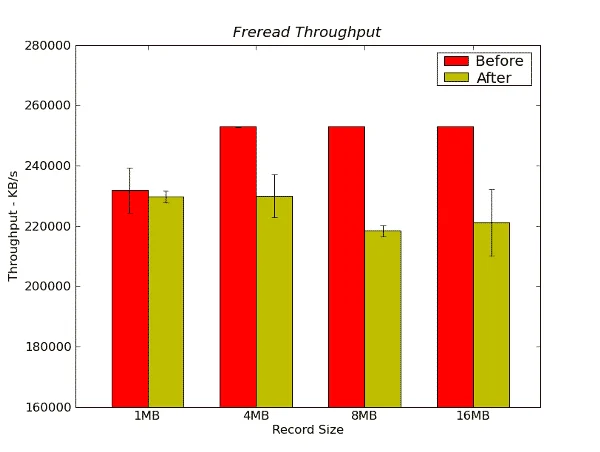
Figure 14 – Freread Throughput Results from IOzone in KB/s
In this last throughput test we do see some difference in the performance before the stress testing as compared to after the testing. The differences in the average performance at the large record sizes (4MB, 8MB, and 16MB) range from about 9% to a little over 13% better for the “before” performance compared to the “after” performance.
Overall we see some differences in the throughput benchmarking. The differences favor the “before” performance for certain tests:
- Random Read (13-15%)
- Random Write (20% for 4MB records)
- Backwards Read (17-20% for larger record sizes)
- Strided Read: (22-23% for larger record sizes)
- freread: (9-13% for larger record sizes)
The random I/O performance difference is very interesting because when many clients applications access the same storage the I/O patterns basically become random to the storage device. Consequently, random performance of the device becomes much more important.
IOPS Results
Recall that four IOPS tests were performed: Write IOPS, Read IOPS, Random Write IOPS, and Random Read IOPS. The results for these four tests is presented in the following four figures.
Figure 15 below presents the Write IOPS results.
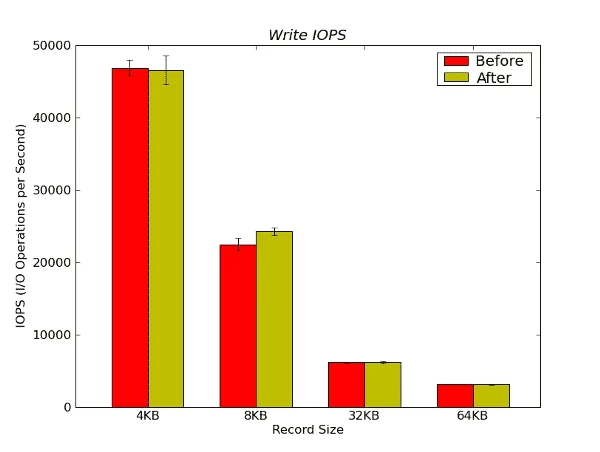
Figure 15 – Write IOPS Results from IOzone in Operations per Second
There is little difference in Write IOPS before and after the stress testing. There might be a small difference at a record size of 8KB, but the standard deviations are very close to each other so the difference in performance is very, very small.
Figure 16 below presents the Read IOPS results.
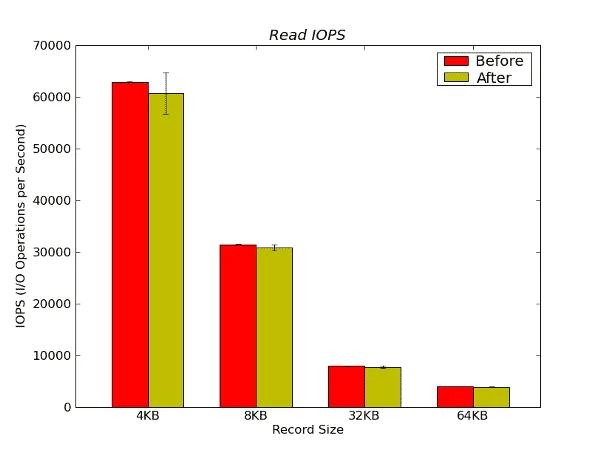
Figure 16 – Read IOPS Results from IOzone in Operations per Second
There is very little difference between the performance before the stress test and after.
Figure 17 below presents the Random Write IOPS results.
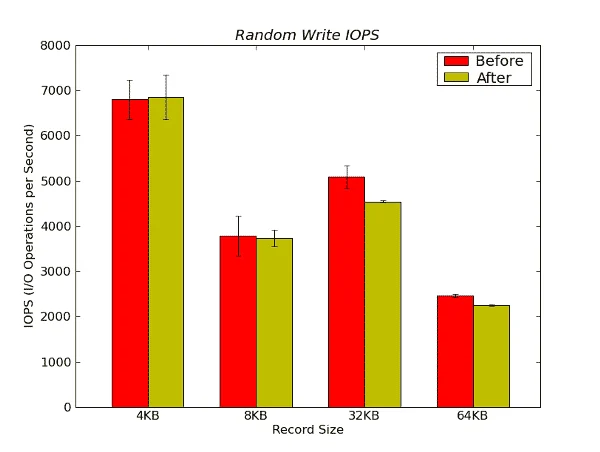
Figure 17 – Random Write IOPS Results from IOzone in Operations per Second
The only real difference in performance between “before” and “after” comes for larger record sizes. For 32KB and 64KB there is some difference with the “before” performance being slightly better. At a record size of 32KB, the “before” performance is about 10.8% better than the “after” performance and at 64KB, the “before” performance is about 8.7% better.
Figure 18 below presents the Random Read IOPS results.
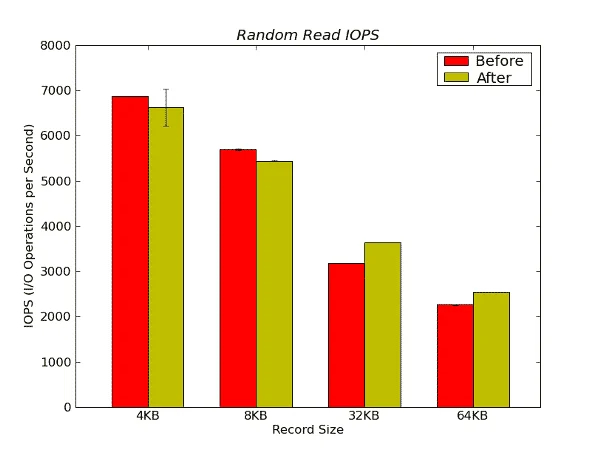
Figure 18 – Random Read IOPS Results from IOzone in Operations per Second
This benchmark result is a little more interesting in that at the larger record sizes, the Random Read IOPS performance is actually better “after” the stress testing than “before”. At 32KB the “after” performance is 14.26% better than the “before” performance and at 64KB the “after” performance is 12.6% beter than the “before” performance.
Overall the difference in IOPS performance between “before” and “after” the stress testing is very, very small. However, we do see some differences in the random IOPS performance between the “before” and “after” benchmarks.
Metadata Results
Recall that there are three metadata results to be presented: (1) File Open/Close performance, (2) File Stat performance, and (3) File Utime performance. Figures 19, 20, and 21 below, present the performance for the “before” and “after” benchmarks.
Figure 19 below presents the Metadata File Create/Close results.
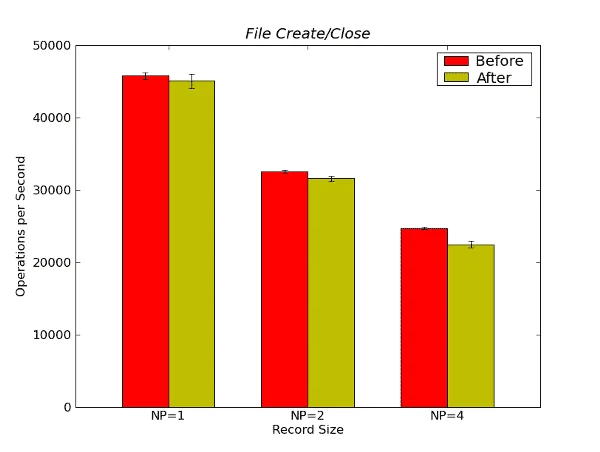
Figure 19 – Metadata File Create/Close Results from Metarates in Operations per Second
The only real difference in performance is with 4 processes (NP=4) where the “before” performance is better (9%) than the “after” performance.
Figure 20 below presents the Metadata File Stat results.
Figure 20 – Metadata File Stat Results from Metarates in Operations per Second
There is some difference in performance between the before and after testing with the “after” performance being 3.88% better at NP=1, 6.58% at NP=2, and 3.44% at NP=4.
Figure 21 below presents the Metadata File Utime results.
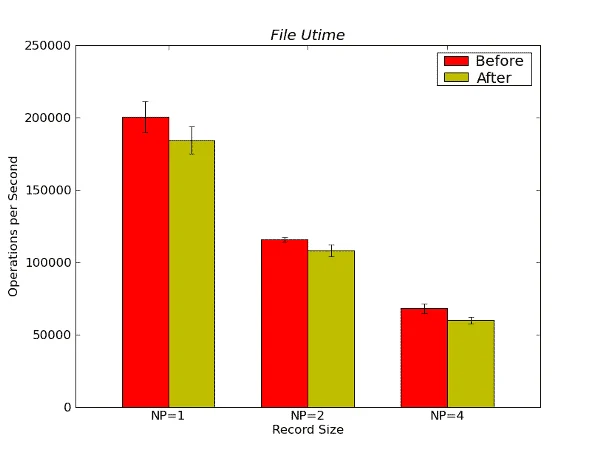
Figure 21 – Metadata File Utime Results from Metarates in Operations per Second
There are some differences in the average performance between the before and after testing for this benchmark. But the difference lies within the standard deviation so it’s impossible to say that one is better than the other.
Interestingly, there are some performance differences in metadata performance, but they indicate that the “after” performance is better than the “before” performance.
Summary
The intent of this benchmarking exercise is to test an enterprise class SSD with a recent Linux kernel version that supports TRIM, and look for performance degradation between a fresh SSD and one that has been through some I/O stress testing.
To compare the performance before the stress testing to the performance after the stress testing, three classes of benchmarks were used – (1) Throughput testing, (2) IOPS testing, and (3) metadata testing. These benchmarks were first run on a clean fresh drive and then on the same drive after it had been subjected to some fairly intense I/O workloads.
An Intel X25-E drive was used for the testing, along with a CentOS 5.4 system with a 2.6.34 kernel that has been patched with bcache. Ext4 was used as the file system because it supports the TRIM command. The drive was configured for the best performance possible on an SSD as was ext4. These recommendations came from a blog by Theodore Ts’o, the lead maintainer of ext4.
Two benchmarks were used for testing – IOzone, which was used for throughput and IOPS testing, and metarates for metadata testing. A total of 13 throughput tests were performed, 4 IOPS tests, and 3 metadata tests. Each particular test was run 10 times and the average and standard deviation were presented in this article.
In general the tests showed little difference between the “before” performance and the “after” performance. However, there were some differences:
- Random Read Throughput: The “before” is much better at record sizes of 4MB, 8MB, and 16MB, with the differences being about 13-15% in favor of the “before” results.
- Random Write Throughput: At a record size of 4MB, the performance before the stress test (“before”) was about 20% better than “after” the stress test
- Backwards Read Throughput: The “before” performance is better by about 17-20% for the 4MB, 8MB, 16MB record sizes.
- Strided Read Throughput: The “before” performance is better by about 22-23% for the 4MB, 8MB, 16MB record sizes
- freread Throughput: The “before” performance is better by about 9% to 13% for the 4MB, 8MB, and 16MB record sizes.
- Random Write IOPS: The random write IOPS performance at a record size of 32KB was better by about 10.82% before the stress testing than after. At a record size of 64KB the performance is better by about 8.73%
- Random Read IOPS: The “after” performance is better at a 32KB record size (14.26% better) and at a 64KB record size (12.6% better).
- File close/open metadata: At NP=4, the “before” performance is is about 9% better than the “after” stress testing performance
- File stat: There is some difference in performance between the before and after testing with the “after” performance being 3.88% better at NP=1, 6.58% at NP=2, and 3.44% at NP=4.
From these results, it looks like the Intel X25-E performed well even after being severely stressed. There are comparisons where the performance before the stress testing was noticeably better than after the stress testing, but there were also benchmarks were the reverse was true (i.e. the performance after the stress test was better). But I think the differences were reasonably small enough over a range of I/O patterns (except for a few unusual ones) that it is safe to say that this particular enterprise class SSD has effectively used various technologies to avoid performance degradation over time.
Sweeping generalizations are difficult to avoid after doing so much testing, but the results indicate that this particular enterprise class SSD has performance that only varies slightly after the drive has been subjected to some fairly severe IO stress. Moreover, it is almost impossible to link cause and effect, but given the poor performance of the early SSDs, it is fairly safe to conclude that the performance and longevity techniques mentioned in this article series, and possibly others, have contributed to this drive being able to perform well over time.
Back to Page 1
Jeff Layton is the Enterprise Technologist for HPC at Dell, Inc., and a regular writer of all things HPC and storage.
Follow Enterprise Storage Forum on Twitter.