The microservices-based software platform offers data analytics, cataloging, optimization, integration, and handles data from the edge.

Hitachi Vantara is updating its DataOps platform with a range of enhancements to help enterprises with the gnarly challenge of managing and utilizing the massive amounts of data they’re generating and holding both in their on-premises data centers and in public cloud environments.
The company, which is the IT and operational technologies (OT) arm of Japanese multinational Hitachi, on August 19 announced the general availability of its next-generation Lumada DataOps Suite, a microservices-based software platform that offers such capabilities as data analytics, cataloging, optimization and integration, and the ability to handle data from the edge.
In addition, Hitachi Vantara unveiled version 9.2 of Pentaho, the data ingestion tool that now supports Microsoft’s Azure public cloud, joining the capabilities it already had with Amazon Web Services (AWS) and Google Cloud and expanding the vendor’s multicloud bona fides. It also expands its support for Cloudera’s Data Platform and Hewlett Packard Enterprise’s Ezmeral Data Fabric software suites.
All of this is aimed at giving organizations the tools they need to collect, identify, tag, curate and analyze data that is coming in from multiple places in an increasingly distributed IT environment, according to Radhika Krishnan, Hitachi Vantara’s chief product officer. The goal of the Lumada suite is to bring together all the data management and artificial intelligence (AI)-driven automation capabilities data scientists and developers need into a single platform.
This drives performance and efficiency for enterprises, Krishnan told Enterprise Storage Forum.
“When we look at the statistics that come through from the industry, we’re finding that while companies are continuing to grow their army of data scientists and data engineers and so on, about two-thirds to three-fourths of the time is actually being spent by these people just cleaning and curating the data,” she said. “The amount of investment going into actually gathering insights and making meaningful use of it is very limited. It’s limited owing to the fact that the actual processing of the data is just an extremely onerous task and there aren’t any clean ways of doing that.”
Also read: Mapping Out a Hybrid Multicloud Strategy
Hitachi Vantara for the past several years has been pulling together the parts that would eventually become the Lumada DataOps Suite. In 2015, then Hitachi Data Systems bought Pentaho, bringing aboard its data integration, visualization, and analytics capabilities. Last year, Hitachi Vantara acquired Waterline Data and its intelligent data cataloging technology — that’s where the DataOps platform gets its AI capabilities — and two months ago bought Io-Tahoe, a division of UK-based energy services company Centrica, which focused on data governance.
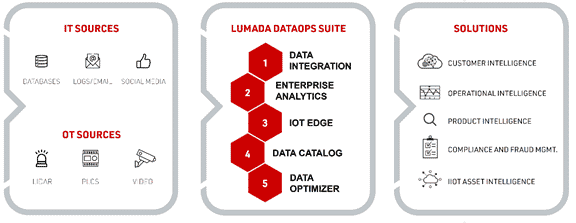
Hitachi Vantara has been adding those capabilities to the Lumada DataOps portfolio, which Krishnan said “allows you to start incorporating features and functionality into that singular platform. You get that ability to scale your data flows. We also support multicloud. Data is resident in multiple places and applications can be designated in multiple places or the user or the consumer can be multiple places. The ability to do this in a multicloud context is what we’re bringing forth.”
Kirshnan also said the self-service feature is a key part of the latest version of Lumada DataOps Suite, enabling organizations to take advantage of the growing range of capabilities in the data fabric. The expanded multicloud features in Pentaho are important at a time when organizations are using multiple public cloud platforms as well as on-premises private clouds.
The Waterline acquisition also led to the “fingerprint” tagging technology. Lumada Data Catalog 6.2, also unveiled this week, uses AI to drive faster data discovery and better data rationalization for better governance and provisioning. The software can intelligently identify and analyze duplicate copies of data and reduce overall storage costs and risks that come with using partial copies for analysis, which can lead to inaccurate insights into the data.
Data has become the coin of the realm in IT and the amount being generated is growing exponentially. Statista analysts are expecting that the amount created worldwide this year will hit 79 zettabytes and grow to more than 180 zettabytes in 2025. They wrote that the growth was more than what had previously been forecast because of an increased demand driven by the COVID-19 pandemic, with more people working and learning from home and using home entertainment options more often.
IDC in March echoed Statista’s findings and noted that data created in the cloud is not growing as quickly as data stored in the cloud, but it’s still growing fast. In addition, the rate of data being created at the edge is almost growing as fast as that in the cloud.
Data — and the ability to quickly collect, store, process, and analyze it — is becoming a key competitive component for enterprises, who see the importance of deriving crucial business information from the data to inform product and services development.
The growing focus on data also is forcing established storage companies to expand their reach into data management.
“It’s fascinating how data storage has now become all about data intelligence and data operations,” Krishnan said. “Previously, these organizations with the customer in mind used to be siloed off. You had a bunch of storage admins who were doing their thing and then you had analytics people or database admins who were responsible for the data sitting within the storage. With the move to cloud computing, and especially as customers have become more exposed to hyperscale environments, which most of them are — they’re doing something other in the cloud, either private or public. The silos have broken down in a pretty dramatic way. Increasingly, it’s no longer that I go to the storage admin with this question on my database admin with a different question. It has become, how can you inject more content intelligence into your data storage so that you’re not just a container for data?”
Organizations are becoming more intelligent in the way they think about what’s sitting in the data, she said. They’re able to target and profile the data and are embracing the notion that integrated data management and data storage gives them dramatically more efficiency, more portability and more flexibility.
“We’re definitely seeing that in the marketplace and we’re taking advantage of it because we do those two things [data management and storage] really well,” Krishnan said. “We’re combining it and taking it to market.”
Jeffrey Burt has been a journalist for more than three decades, the last 20-plus years covering technology. During more than 16 years with eWEEK, he covered everything from data center infrastructure and collaboration technology to AI, cloud, quantum computing and cybersecurity. A freelance journalist since 2017, his articles have appeared on such sites as eWEEK, The Next Platform, ITPro Today, Channel Futures, Channelnomics, SecurityNow, Data Breach Today, InternetNews and eSecurity Planet.

Enterprise Storage Forum offers practical information on data storage and protection from several different perspectives: hardware, software, on-premises services and cloud services. It also includes storage security and deep looks into various storage technologies, including object storage and modern parallel file systems. ESF is an ideal website for enterprise storage admins, CTOs and storage architects to reference in order to stay informed about the latest products, services and trends in the storage industry.
Property of TechnologyAdvice. © 2026 TechnologyAdvice. All Rights Reserved
Advertiser Disclosure: Some of the products that appear on this site are from companies from which TechnologyAdvice receives compensation. This compensation may impact how and where products appear on this site including, for example, the order in which they appear. TechnologyAdvice does not include all companies or all types of products available in the marketplace.








