


Data archiving is the process of transitioning inactive or historical data to inexpensive offline storage where it can be retained for future reference or to meet regulatory compliance requirements. Data archiving frees up the enterprise’s resources by ensuring that its fast storage media and processors aren’t bogged down by older files or data that’s not relevant for day-to-day business operations while preserving that data for future reference or to meet legal obligations. This article provides a closer look at the process and benefits of data archiving and best practices for archiving legacy data.
What is Data Archiving?
Data archiving is a means of saving dated or less-relevant data to offline repositories. For enterprise organizations that collect and consume massive amounts of data, storing and processing data on that scale can get expensive—especially when it is stored on faster media, like flash, to facilitate rapid access and analytics for business intelligence.
As the volume of data grows, the system’s ability to process it also begins to decline. Deleting less-relevant data can keep systems functioning at their peak and reduce storage costs. But there are a few reasons why organizations might want to retain old data, even when it is no longer used in their day-to-day work.
In some cases, legal or governing bodies require enterprises to retain data. Compliance regulations often stipulate the time period that businesses must legally hold onto certain data. Businesses facing lawsuits or other legal actions might also need to present documentation to support their case or to meet a court demand. Archived data can be searched and examined using new technologies like e-discovery, even when the artifact data and documents are decades old.
As a best practice, enterprise IT departments identify old or seldom used data and move it from active databases and repositories to inexpensive “offline” storage media, from which it can be retrieved when necessary.
How Does Data Archiving Work?
Data archiving starts with IT working with stakeholders to develop data retention policies that identify the types of aging or obsolete data and determine how long they will be retained before they are purged. Data retention policies must conform to both regulatory requirements for keeping data and internal decisions about the usefulness of data for historical research purposes.
Once data retention policies are defined, IT moves the old and obsolete data they identified to cold storage. Cold storage refers to slow, dependable storage—often hard disk drives—that are affordable and easy to maintain; hot storage is fast media where data is stored and accessed regularly and rapidly for processing or analytics. Data can be retrieved from cold storage, but it takes time, making it not feasible for operational data.
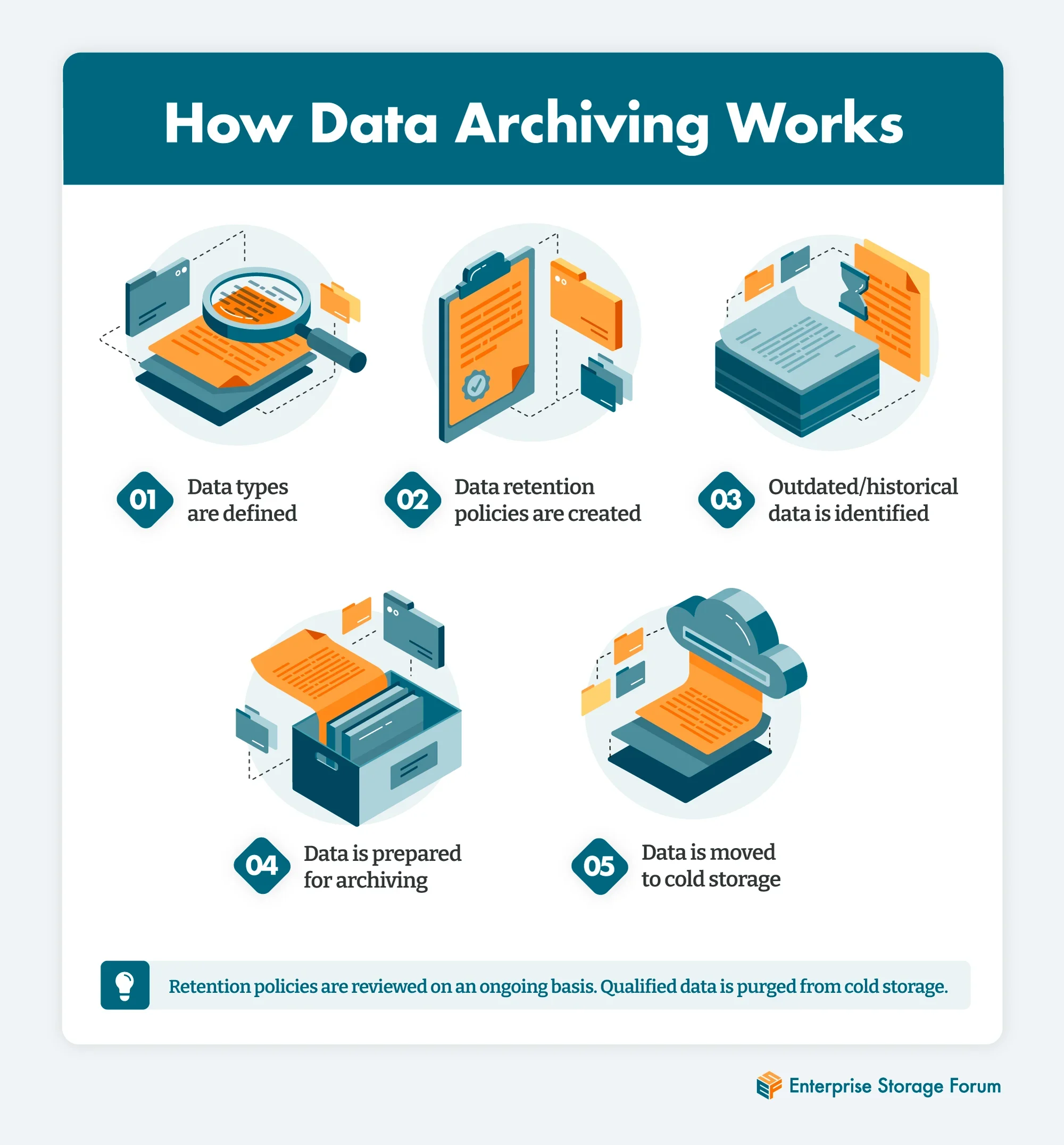
Because archived data is not ordinarily used by the enterprise, data archiving may only be done annually or semi-annually.
Data retention policies are living documents. Enterprise IT leaders must keep up to date with regulatory and legal requirements and meet with compliance bodies and internal stakeholders to determine if and when they need to be revised. Once data retention policies have been reviewed and approved, archived data that exceeds designated retention timeframes can be purged.
The Benefits of Data Archiving
Complying with data retention regulations is the main driver behind many enterprise data archiving efforts, but there are a few other benefits to consider.
One is cost—fast storage is expensive, and old data can be archived to cold storage more affordably. Another is performance. Shifting old records from databases to archives frees up systems to run more efficiently and more rapidly, improving the speed of transactions and the quality of searches.
Businesses can also benefit from saving historical data in the event of legal proceedings. For example, if there’s an alleged patent violation, archived data can become “active” if proof is believed to exist in archived data. Corporate legal teams are increasingly using e-discovery services that provide cloud-based legal searching through archived data, making it worth keeping even after it has become irrelevant to the day-to-day operations of the business.
Data Archiving Best Practices
While the concept of data archiving is straightforward, there are some best practices to take to ensure success. Here are eight industry standard best practices for archiving data.
Identify and Sort Data Before Archiving
There are many kinds of data and systems. In most cases, data archiving classifications will closely align with classifications for active data. Each data type from every system should be categorized to create a complete taxonomy of all data under management. This enables IT and end users to determine individual data retention policies for each type of data that must be archived and helps determine whether it is more effective to move some data types to their own archives. For example, you might decide to store system-of-records data and emails in one archive and large, unstructured data objects like documents and photos in another.
Select the Right Archiving Tool
Data archives need to be searchable. IT decisions must consider not only which storage media to use for archived data but which tools to use so that archived data can be easily indexed, searched, and retrieved. There are many options for data archiving software on the market, as well as data archiving services.
Seek a Cold Storage Solution
The goal for archived data is simply to retain it—retrieval may be infrequent, or it may never happen. From a storage standpoint, the least expensive form of reliable, accessible storage should be used. Commonly, this is cold storage based on slow hard disk drives that offer high capacity and low speeds at affordable prices.
Maintain Cold Storage
Cold storage should not be a set-it-and-forget-it situation—it should be checked regularly as part of the scheduled data archiving timeline and storage media should be well maintained. Done right, data archiving can offer peace of mind, but done wrong, a business might try to retrieve needed files from offsite storage only to find it corrupted.
Review Data Retention Policies
Enterprises should have documented data policies for archived data. These policies inform IT decisions about which data to keep and which to purge on, at minimum, an annual basis. Since data and retention needs can change, data retention policies should be reviewed with users and regulators on a regular basis. Regulators, auditors, and attorneys often know about new data retention requirements before they are enacted, and it can be helpful to get out in front of them.
Schedule Data Archiving Timelines
Data archiving should not be a haphazard process. It should be a regular part of an enterprise data management strategy, and done regularly. For most organizations, an annual schedule is sufficient—others may prefer to do it semi-annually.
Purge Data When Appropriate
The main intent of data archiving is to preserve old and/or obsolete data that could be needed for research or legal purposes. However, it’s just as important to keep archived data clean by removing any data older than the retention limits stated in policies. This makes data search and retrieval operations more efficient and reduces storage and processing.
Data Backup vs. Data Archiving
On the surface, data archiving is similar to data backups—both involve moving data to storage devices not being used by active business systems. But the goals are different. Data backups are used to copy active data to offline storage as a redundant failsafe in case the active systems fail. The business’s most critical data is what’s being backed up. In data archiving, only dated or obsolete data is stored—and it’s retained for historical purposes, not for active use.
The decisions and the operations that IT performs for data backups and data archiving are also different. Data backups need fast, expensive storage that can rapidly restore data lost or compromised on live systems. The data must be current, so it is backed up nightly or throughout the day. In data archiving, the movement of data to storage is often done infrequently—usually once each year—and to slow, inexpensive storage media.
Bottom Line: Enterprise Data Archiving
Data archiving should be part of every enterprise’s data management strategy, but many organization’s fall short. As the volumes of data gathered grow, the cost of storing it does, too—but it’s the potential cost of a compliance violation or legal misstep that could be more damaging.
Creating, reviewing, and updating data retention policies can help ensure that the business is keeping the most critical data in active storage and moving outdated or historical data to offline storage. But these policies will also determine how long archived data of all types is kept.
Data archiving is not simply an action taken by IT. It’s a company-wide initiative into which all affected stakeholders should have input. It should be enforced and communicated across staff, and it should be revisited and revised at regular intervals in collaboration with legal advisers and compliance regulators. A good data archiving strategy can help organizations find the balance between the cost of storing data and the cost of not storing it.
To learn more about the techniques businesses use to safely manage and store their data, read 12 Best Practices for Enterprise Data Storage Security next.